人工智能资讯 第18页
聚合当前分类下的最新内容,按时间顺序查看第 18 页精选文章。

皮查伊在斯坦福被嘘:学生不是反 AI,是在查 Google 的合同
Google CEO 皮查伊在斯坦福毕业典礼演讲时,遭约 200 名毕业生退场和现场嘘声。抗议焦点不是泛泛反 AI,而是 Project Nimbus、ICE,以及 Google 把云和 AI 能力卖给军方与执法机构。真正要看的,是 AI 巨头会不会给政府客户设边界,还是继续用“造福人类”覆盖所有合同。

Anthropic 下线 Fable 5、Mythos 5:AI 采购多了一个行政风险
美国商务部以未公开出口管制指令要求 Anthropic 限制非美国人访问 Fable 5 和 Mythos 5,公司随后为合规将两款模型对所有客户下线。争议点不只是 Fable 5 是否存在 guardrail bypass,而是行政执法信已经足以改变 AI 核心产品的可用性。对 AI、云服务和安全团队来说,模型采购现在要把政策中断风险写进清单。
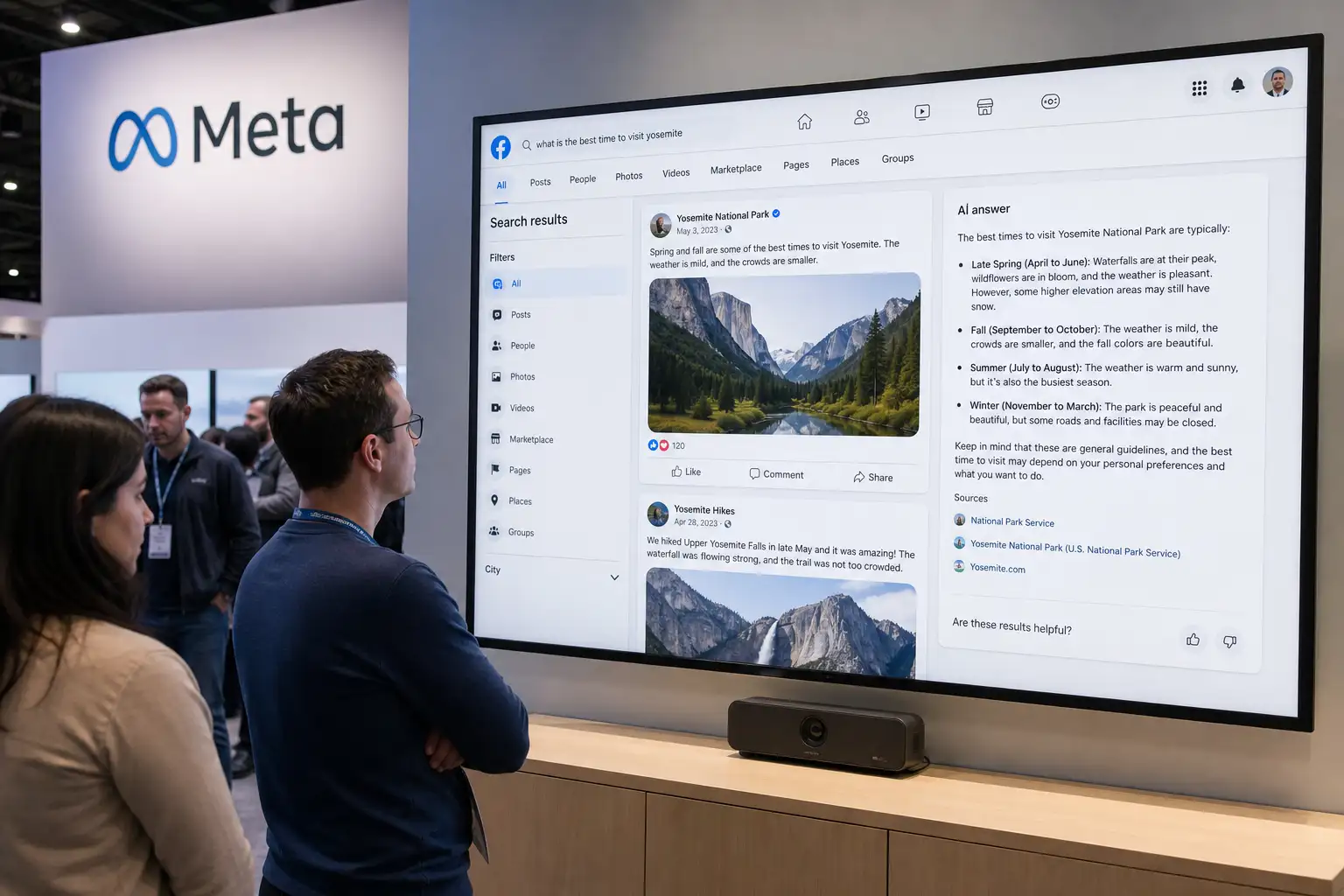
Meta 给 Facebook 搜索加了 AI,但真正被改写的是公开发言
Meta 在 Facebook 搜索中加入 AI Mode,和 People、Marketplace 等模式并列,答案来自 Facebook、Instagram、Threads 等公开内容,并支持继续追问。 它不是独立搜索引擎,也不是读取私密帖子的证据;真正的变化是,公开发言被平台重新打包成可回答、可分发的 AI 资产。 普通用户要重新理解“公开”的代价,创作者则要盯紧来源标注、流量回流和语境保留。
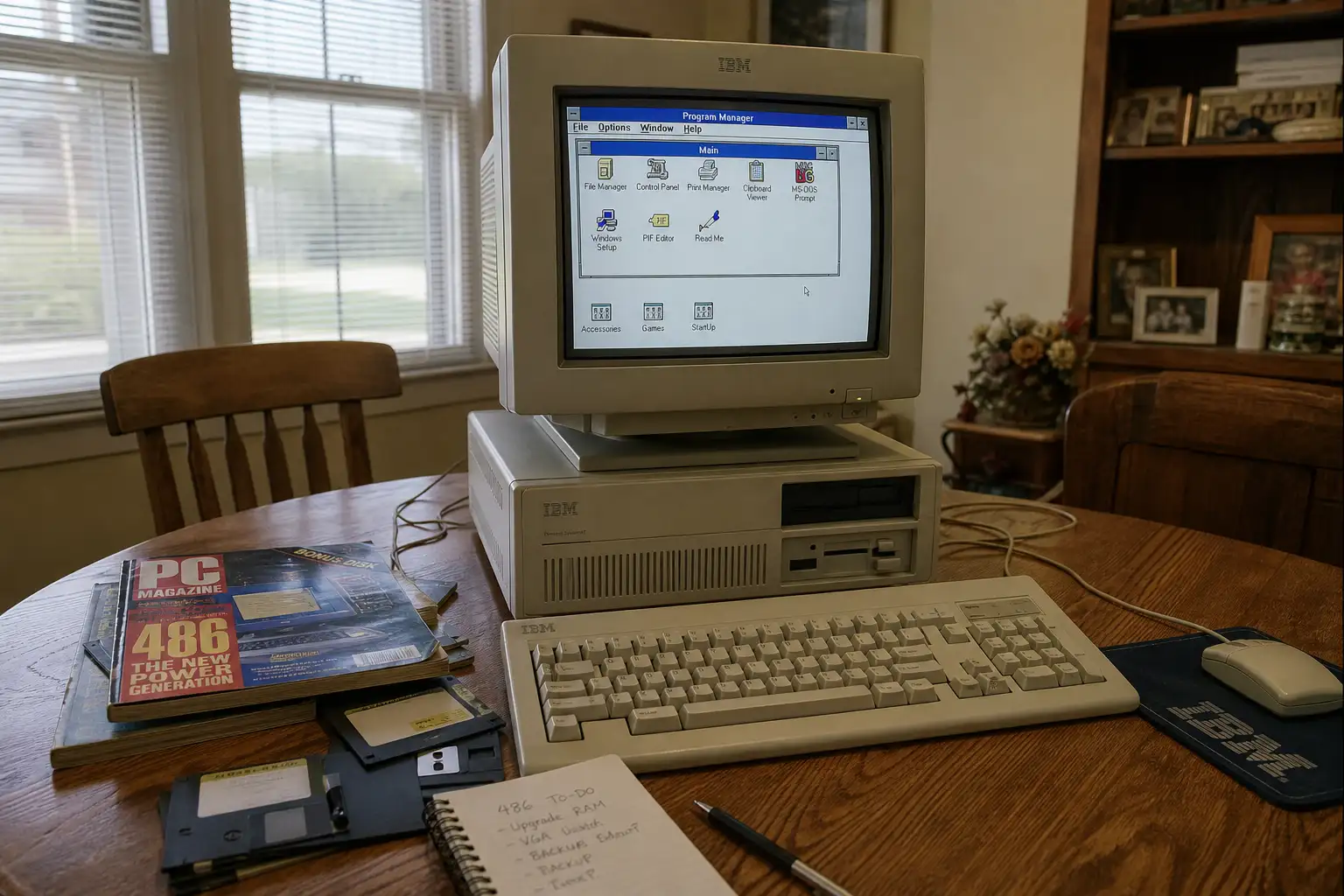
一个老程序员说“I love the computer”:他反感的不是电脑,是 AI 生意
Michael Enger 借 Chris Person 在播客里的“I love the computer”,回看自己从 IBM 486、纸质电脑杂志、早期 Web 到编程职业的路径。文章真正的判断不是怀旧,而是区分:计算机文化仍值得热爱,正在败坏它的是广告、围墙花园和把开源劳动打包出售的 AI 商业激励。对开发者和创作者来说,接下来要看的不是模型口号,而是授权、退出机制和可替代工具是否还在。

《Disclosure Day》最不现实的地方:外星人视频播出后,人类竟然信了
404 Media评论的是斯皮尔伯格新片《Disclosure Day》,不是一次真实外星人披露;本文涉及关键情节剧透。它抓住的漏洞很准:在AI视频、阴谋论和媒体信任下滑之后,外星人公开视频更可能被当成造假、宣传或噪音。真正受考验的不是外星人叙事,而是视频证据还能不能让人形成共识。

白宫想把 AI 联邦优先权和 KOSA 打包,Big Tech 的交易变难了
白宫正考虑把 Big Tech 想要的 AI 联邦优先权,和参议员 Marsha Blackburn 版本的 KOSA 绑定推进,但目前仍是谈判和泄露方案。Big Tech 要的是全国统一 AI 规则,代价可能是接受更重的儿童安全责任。真正的卡点在国会:两院版本不一、民主党未必买账、暑期休会前窗口很窄。

白宫要求 Anthropic 下线最强模型,主权 AI 突然不再像口号
据 The Verge 报道,应华盛顿要求,Anthropic 在周末突然下线 Fable 5 和 Mythos 5,并被要求阻止所有外国国民访问,范围甚至包括公司内部外籍员工。真正要看的不是模型何时恢复,而是美国前沿 AI 的访问权已经被政府安全逻辑直接接管;这给各国推动主权 AI 递上了一份现成理由。

白宫要求限制外国人访问 Anthropic 新模型,真正麻烦的是“模型也会被管制”
白宫 6 月 12 日以国家安全为由,要求 Anthropic 限制外国人访问 Fable 5 和 Mythos 5,Anthropic 随后对所有客户关闭两款模型访问。 争议焦点不是已有攻击或泄密,而是一个“狭窄潜在越狱”是否足以触发商业模型下线。 对依赖美国前沿模型的企业和开发者来说,采购风险不再只看能力、价格和 SLA,还要看美国行政指令会不会突然改变可用性。

Meta把AI Mode塞进Facebook:搜索更省事,答案也更难全信
Meta在Facebook推出AI Mode,用Meta AI汇总公共帖子、Groups和Reels等公开内容,直接生成搜索答案。 关键变化不是多了一个聊天入口,而是Facebook把多年社区讨论变成可消费的答案。 便利会提升,风险也会放大:普通用户讨论不等于权威来源,创作者和群组运营者需要重新看待公开内容的流向。

本地大模型能替代 Claude 写代码了吗?开发者的答案开始分叉
Hacker News 上一场关于本地大模型编码的讨论显示,个人项目已经有人取消 Claude/GPT 订阅,改用 Qwen 3.6、Gemma 4 等约 26B-35B 模型。但在职业开发场景,多数反馈仍认为本地方案难以全面替代 Sonnet、Opus 等前沿模型,差距不只在模型质量,也在硬件、上下文、速度和工具链体验。真正的判断不是“能不能跑”,而是省钱、隐私和可控性是否足以抵消返工、配置和维护成本。

把 AI 编码代理关进 Git:一个 homelab 运维方案的真正价值
一名 homelab 用户把 OpenCode Web UI、Git 权限隔离和 GitOps 部署串成了一套个人 AI 开发平台,用来维护十来个 Docker Compose stacks 和配置变更。它的价值不在于让 AI 自动运维,而在于把 AI 编码代理限制在 feature branch 和 PR 审核里,让省时间与控风险同时成立。短板也清楚:AI 看不到真实服务,CI 日志反馈受 Forgejo Actions API 限制,闭环还不完整。

Meta 被成人视频公司告了:AI 数据饥饿,不能靠“员工摸鱼”糊弄过去
美国加州北区联邦法官驳回 Meta 撤诉请求,允许 Strike 3 Holdings 继续起诉 Meta 涉嫌通过公司 IP 批量 BT 下载并传播 2396 部成人视频。 Meta 尚未被判侵权,法院也未认定这些视频被用于 AI 训练;但法官认为“员工个人行为”的解释难以令人相信。 这案子刺中的不是成人视频猎奇,而是 AI 公司数据来源的审计问题:公司吃下规模红利,就不能出事后把账切给个人。

Claude Mythos/Fable 下线:Anthropic 输在一道越狱题之外
Axios 披露,Claude Mythos/Fable 被暂停访问,牵涉美国政府出口管制、jailbreak 风险,以及 Anthropic 与政府部门之间的信任摩擦。Anthropic 仍称触发事件是“潜在的狭窄、非通用 jailbreak”,并未承认存在 universal jailbreak。真正的变量不是某个补丁能不能写出来,而是前沿 AI 公司能否把安全证明、政策沟通和监管信任放进同一套系统里。

Salesforce 36亿美元买Fin:客服AI先进入巨头收编期
Salesforce宣布以36亿美元收购AI客服平台Fin,交易预计在Salesforce 2027财年第四季度完成,约为自然年2027年前几个月。官方说法很明确:Fin团队和技术会用于增强已有的Agentforce,而不是另起炉灶。真正值得看的是,企业AI代理的竞争正在从“模型多强”转向“能不能接管流程、算清ROI”。

手摇 AI 是个笑话,但它戳中了云端 AI 的三根软肋
CrankGPT 更像一个讽刺概念页:手摇、脚踏供能,本地私有运行 AI,卖点是不用 Wi-Fi、不怕宕机、不把数据交给大公司。它真正有意思的地方,不是硬件是否可行,而是把 AI 的算力依赖、能源账单和平台定价权摆到台面上。对开发者和独立创作者来说,重点不是立刻逃离云端,而是别把数据、接口和工作流全押在单一平台。
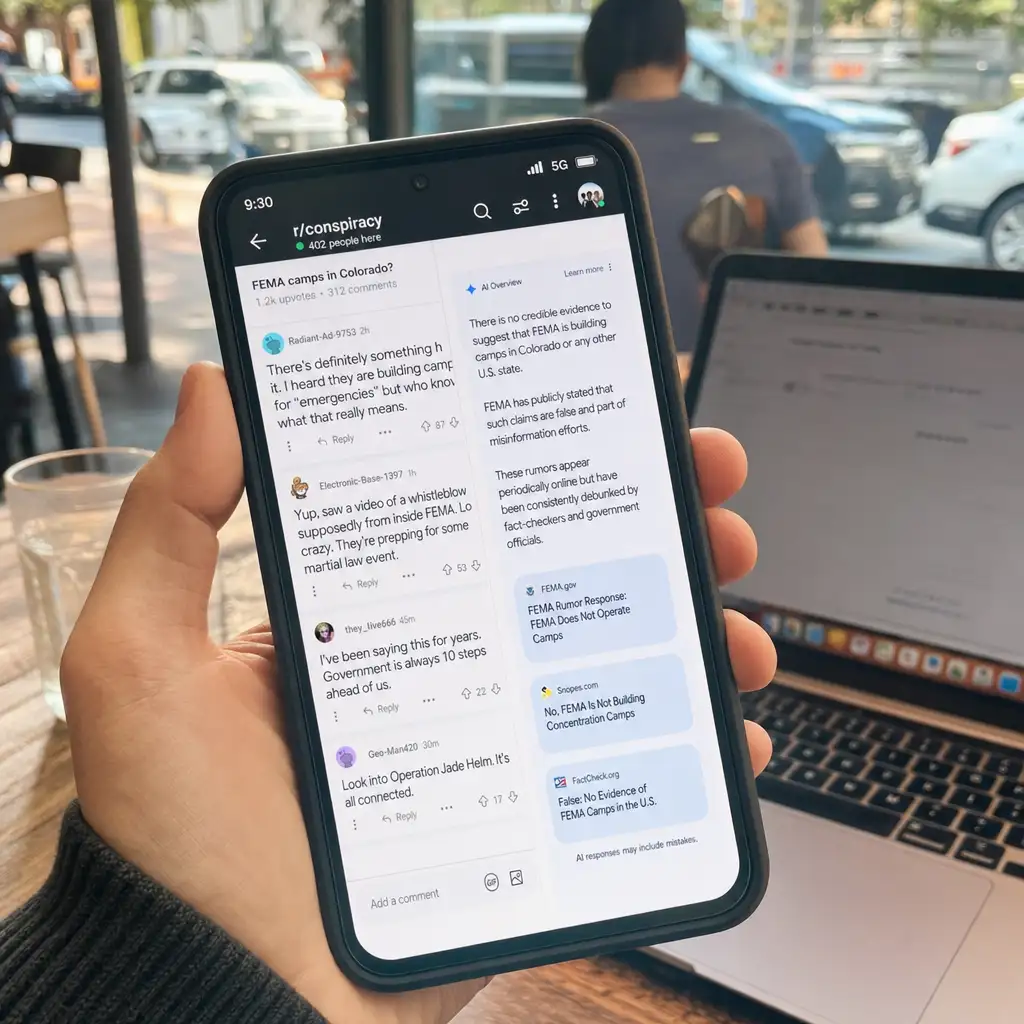
13 个词操纵 AI 搜索?真正危险的是答案里的信任外包
康奈尔一篇预印本研究显示,在 Reddit、Wikipedia、Quora 等 UGC 内容里插入短至 13 个词的相关文本,就可能影响 ChatGPT、Google AI Search 等深度研究代理的回答与引用。研究没有污染真实 Reddit,而是在沙盒检索层测试机制。麻烦不只是垃圾内容变多,而是 AI 搜索把社区文本当信任来源,又把这种信任放大成了答案。

Sarvam融资2.34亿美元:印度AI独角兽真正卖的是什么
Sarvam以15亿美元估值完成2.34亿美元融资,HCLTech投入1.5亿美元并担任领投战略投资方。它还不是印度版OpenAI,但这笔钱说明,本土基础模型、印度语言AI和政府企业场景,正在变成可采购的生意。接下来要看的不是估值,而是交付成本、客户复购和HCLTech能带来多少真实项目。

OpenRouter Fusion API:多模型会诊来了,但账单也会一起变复杂
OpenRouter 展示 Fusion API,模型 slug 是 `openrouter/fusion`,一次提示会交给多个专家模型并行分析,再由 judge 模型整合答案。它更适合研究、审阅、复杂决策这类怕错的任务,不适合追求低价单次调用。费用按实际调用的分析模型和 judge 调用累加,开发者需要在 Activity 里核对本次到底跑了哪些模型。

Salesforce拟36亿美元收购Fin:客服AI开始拼交付速度
Salesforce已签署最终协议,拟以约36亿美元收购Fin,交易预计在其2027财年第四季度完成,仍需监管批准和常规交割条件。 这笔交易的关键,不是Salesforce又买了一家公司,而是Fin能否补上Agentforce在客服AI代理快速部署上的短板。 对企业软件观察者和AI客服采购方来说,真正要盯的是整合方式、价格合约和数据治理,而不是发布会口号。

Yam-9把VLM送上轨道:卫星遥感的筛选工作开始前移
2026年4月,Loft Orbital的Yam-9在轨运行NASA JPL的NAVI-Orbital和Google DeepMind的Gemma 3,用自然语言任务识别地球观测图像中的目标。关键变化不是卫星“会思考”,而是部分图像判读和数据筛选被推到轨道端。短期价值在于减少原始数据下传和人工初筛,长期能走多远,要看星座规模、功耗、内存和模型稳定性。

AI竞赛换赛道了:不只拼模型,还要拼刹车、测速和成本
Import AI 461把几条前沿动向放在一起看,信号很清楚:AI行业的分水岭正在从“谁的模型更强”转向“谁能可靠评测、低成本运行,并在失控前建立安全边界”。Sequent的安全焦虑、FrontierCode的高难代码评测、小米的高速推理,都在说明同一件事:参数战还没结束,但已经不够用了。