人工智能资讯 第23页
聚合当前分类下的最新内容,按时间顺序查看第 23 页精选文章。

Claude Fable 5 隐形护栏翻车:Anthropic 道歉不冤
Anthropic 为 Claude Fable 5 的隐藏反蒸馏护栏道歉:原方案会在疑似蒸馏请求中降低或改写回答质量,却不提示用户。公司现在改为触发时明确提示,并把相关请求回退到 Claude Opus 4.8。真正的争议不是反蒸馏该不该做,而是前沿模型公司能不能把商业防御藏进“安全”黑箱里。

Hugging Face 拆解 torch.compile:单个 Linear 变不出奇迹,MLP 才有融合空间
Hugging Face 发布 PyTorch Profiling 系列第二篇,用 profiler 对比 nn.Linear、GeGLU MLP 和 torch.compile 后的执行路径。关键判断很克制:compile 通常不改变 GEMM 本身,主要省 CPU 调度链,并融合 GeLU、mul 这类 pointwise kernel。对做 PyTorch 性能优化的人,重点不是问“compile 快不快”,而是先看瓶颈在 GEMM、dispatch,还是小算子链。

AI还没吃掉程序员,但正在改写程序员的价值
把科技公司裁员都归因于AI,目前证据不够。Block、Snap、Intuit这些案例更像成本压力、投资人施压和组织重组被套上了AI叙事。 真正的变化在工程岗位内部:AI压缩写代码环节,但决策、验证、交付和责任还在团队手里。软件工程师需求没有崩塌,招聘变慢、初级岗位承压、评价标准变硬。

OpenAI支持欧盟AI内容透明度准则:合规姿态更清楚,技术边界也更清楚
OpenAI明确支持欧盟委员会发布的《AI生成内容透明度行为准则》,并把这件事接到它在欧洲的可信AI合规叙事里。它强调C2PA元数据、SynthID水印和openai.com/verify等多重来源信号,但这些工具只能提高可追溯性,不能保证内容永远防伪。对AI合规团队和内容平台来说,真正要调整的是采购、审核和发布流程。

Deezer把AI音乐检测推向Spotify歌单:平台不接,就让用户先查
Deezer推出AI音乐检测网站,用户授权后可扫描约20个流媒体平台的歌单,包括Spotify、Apple Music、SoundCloud和YouTube Music。它真正想推的不是一个小工具,而是把AI音乐标识从平台内部决策,挪到用户可见的位置。检测结果目前只能当提示,不能当定论;平台合作、准确率和误判处理都还没真正落地。

Pokémon Go 玩家扫街数据,正在变成无人机的导航底料
Niantic Spatial 用 Pokémon Go 玩家多年提交的约 300 亿次环境扫描训练视觉定位系统,并与美国防务地理情报承包商 Vantor 合作,目标是无 GPS 环境下的无人机和机器人导航。 争议不在 VPS 技术本身。关键是玩家为游戏奖励提交的数据,能不能在可转让、可再授权条款下,被一路转译成防务能力的训练燃料。 接下来最该看三件事:Niantic 是否披露训练边界,Vantor 是否说明模型历史来源,2026 年初外场测试后是否进入更广泛采购。

OpenAI考虑砍token价:模型战开始变成入口战
据 WSJ 报道,OpenAI 正考虑显著下调 AI 产品 token 收费;CNBC 向 OpenAI 求评,截至报道发布未获即时回应。它还没有正式降价,也没有公开幅度和时间表。真正的信号是:头部 AI 公司开始从模型领先,转向价格、留存和入口争夺。

Anthropic 调整 Claude Fable 5:研究请求不该被静默降效
Wired 记者 Maxwell Zeff 报道,Anthropic 将调整 Claude Fable 5 面向前沿 LLM 开发请求的防护策略,让相关限制变得可见,并为此前权衡失当道歉。争议不在安全防护本身,而在用户不知情时,模型是否可以暗中降低研究请求的有效性。最受影响的是用 Claude 辅助前沿大模型研发的研究者和团队,他们需要知道工具边界,而不是猜测模型为什么突然“不好用”。

Opendoor撤出印度:AI没打穿外包,但人海流程的账开始不好算了
Opendoor关闭开设不到两年的印度业务,CEO Kaz Nejatian称运营要回流美国、靠近客户,并转向更小的AI原生团队。 这不是“AI击穿印度外包”的证据。更准确的说法是:住房市场压力、公司缩编、AI自动化,一起在重算低成本人力外包的旧账。

datasette-agent 0.2a0:Agent 会写 SQL 不稀奇,会停下来问人才稀奇
Simon Willison 发布 datasette-agent 0.2a0:工具现在能在执行中向用户提问、暂停流程,并把未回答问题持久化。新增的 save_query 可保存 Agent 生成的 SQL,但必须展示完整信息并由用户点击 Yes。看点不在功能有多大,而在 Agent 开始把“副作用发生前让人接管”做进产品流程。

“93%匹配”之后被捕:佛罗里达人脸识别案的关键不是算法错了,而是警方信了多少
佛罗里达男子 Robert Dillon 起诉多地警方,称自己因人脸识别“93%匹配”被错误逮捕并遭起诉,相关指控后来已被检方撤销。诉状的重点不只是算法误报,而是警方是否把相似度分数当成调查结论,并遗漏了可排除嫌疑的信息。对 AI 执法和司法科技从业者来说,这案子真正要看的,是人脸识别结果能不能进入逮捕令材料、以什么身份进入、由谁负责核验。
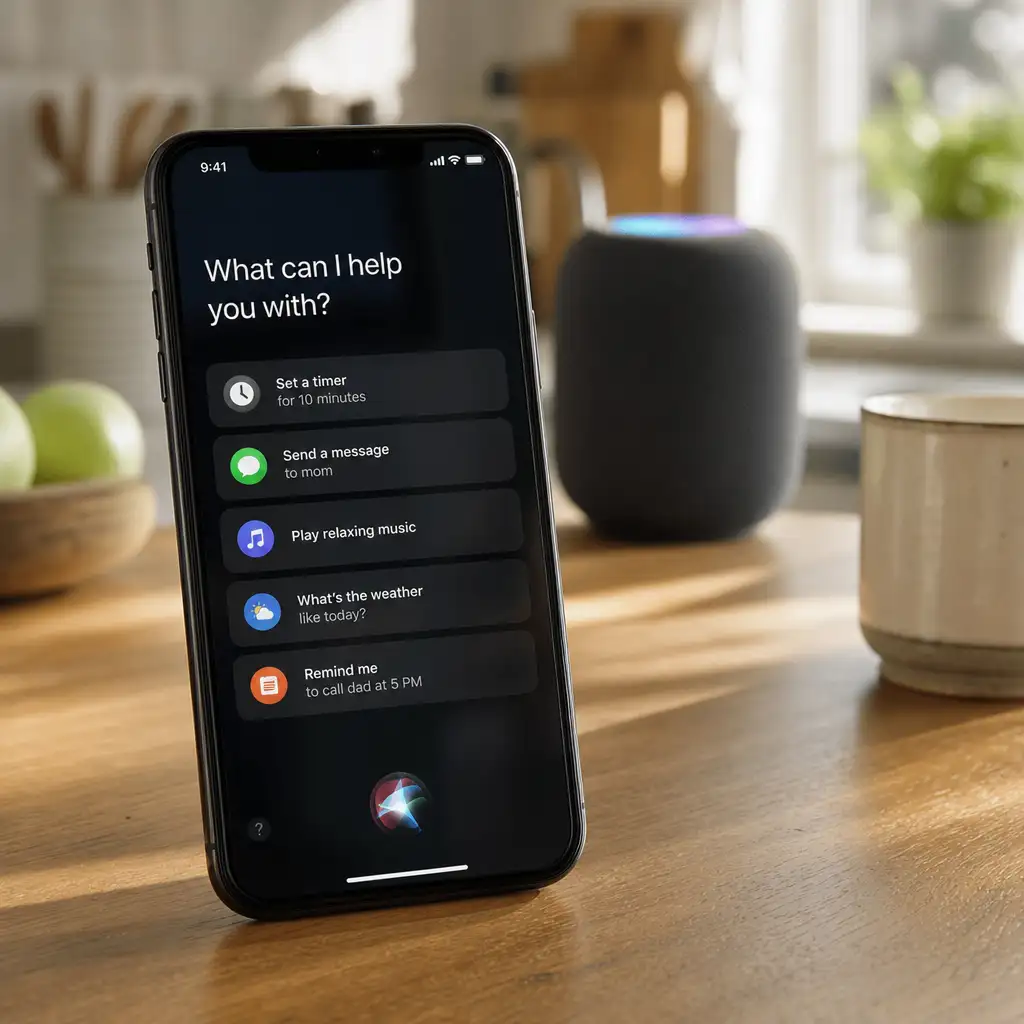
新 Siri AI 还没证明自己更聪明,但先学会了闭嘴
The Verge 记者试用 WWDC 2026 后的新 Siri AI,发现它比 Gemini、ChatGPT 更短、更冷、更像工具。 这不等于 Siri 已经追上主流 AI 助手;目前能判断的只是交互气质:苹果把它放在“办事入口”,而不是“陪聊对象”。 对苹果用户来说,iOS 27 秋季公开发布前不必急着为 AI 换机或改工作流;更该看它到时能不能在复杂任务里少说也能办成事。

OpenAI 接入 Oracle 云承诺:企业 AI 开始拼采购通道了
OpenAI 与 Oracle 合作,未来数周内,符合条件的 OCI 企业客户可用 Oracle Customer Hub/UCM credits 访问 OpenAI 前沿模型和 Codex。关键不在“多一个入口”,而在 OpenAI 正把模型塞进企业已有云预算、采购流程和治理框架。别读过头:这不是免费开放,也不是宣布 OpenAI 模型原生部署在 OCI 上。
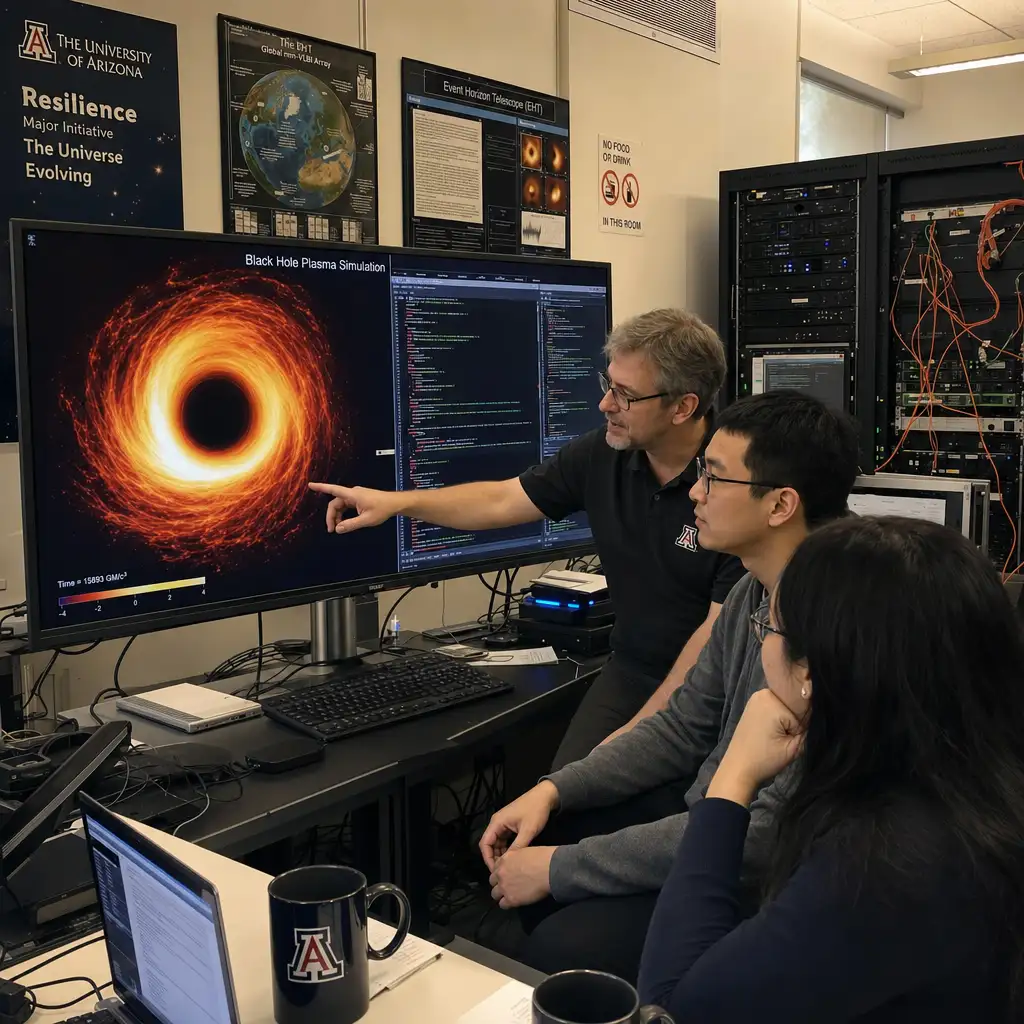
Codex 进了黑洞模拟,但关键不是 AI 会算黑洞
亚利桑那大学和 Steward Observatory 研究者 Chi-kwan Chan 正在用 OpenAI Codex 辅助推导、实现和测试黑洞附近等离子体的数值算法。重点不是 AI 已经解决黑洞模拟,而是它能把候选算法更快送进可读、可测、可复现的流程。对 AI 科研应用读者,判断标准应从演示效果转向验证链;对高性能计算读者,变量在于算法能否减少无效的小时间步开销。

杨安泽不等华盛顿了:Noble Mobile能返钱,但补不了AI分配缺口
杨安泽在 TechCrunch Equity 播客中谈到,他不再只等华盛顿推动 UBI 或 AI 劳动力政策,而是用 Noble Mobile 这类创业项目先做实验。Noble Mobile 的卖点是奖励用户少用手机,对抗注意力经济;它有现实价值,但更像行为激励,不是 AI 时代的分配方案。真正要看的不是产品口号,而是返钱从哪里来、能覆盖谁、能不能长期成立。

xAI 工程师起诉风波:Grok 安全警报撞上 SpaceX IPO
前 xAI 工程师 Devin Kim 起诉 xAI 及其母公司 SpaceX,称自己因多次警告 Grok 安全风险,在 2025 年 9 月被解雇。 这仍是起诉书指控,不是法院认定;但它把一个关键问题推到台前:当发布速度、模型性能和上市叙事相撞时,AI 安全有没有真正的否决权。 最该看的不是 Grok 又出争议,而是 xAI 接下来能否拿出可验证的安全流程、内部权限和测试记录。

Google 开放 DiffusionGemma:扩散式文本生成从演示走向可调用模型
Google 将此前短暂露面的 Gemini Diffusion 研究,以开放权重 Gemma 模型 DiffusionGemma-26B-A4B-it 形式发布,并采用 Apache 2 许可。它的重要性不在于又多了一个大模型,而在于高速扩散式文本生成第一次更接近开发者可下载、可调用、可评测的形态。

Google DiffusionGemma:4 倍速度背后,本地 AI 开始换赛道
Google DeepMind 发布实验性开放模型 DiffusionGemma,用扩散式文本生成一次并行产出最多 256 个 token,部分硬件上宣称约为同级自回归 Gemma 的 4 倍速度。它真正指向的不是替代 Gemini,而是本地 AI 的效率路线:用计算换带宽,用并行压低延迟。开发者可以试,但不该急着迁移;短输出、错误率和部署成本还没算清。

Anthropic CEO 主张前沿 AI 强制测试:透明度监管可能不够用了
Anthropic CEO Dario Amodei 在 2026 年 6 月发文称,前沿 AI 的风险已经不能只靠披露和观察来处理,算力阈值以上的模型应接受第三方测试和审计。真正的变化,是监管类比从社交应用、加密货币,转向飞机、汽车和药品:上线前要测,出事后可限制、撤回或阻断部署。对 AI 公司、企业采购方和投资人来说,这意味着发布节奏、合规成本和估值逻辑都要重新计算。

德国法院给 AI 搜索划线:Google 不能把错误摘要当普通链接
德国一项临时裁定认为,Google 需为 AI Overviews 生成并传播的虚假陈述承担责任,相关错误内容不得继续展示。关键不是 AI 搜索被禁止,而是法院把 AI 摘要看成 Google 自己的新陈述,不是第三方网页的被动展示。对 AI 搜索团队和企业品牌方来说,纠错、引用、下架机制会变成硬成本。

Claude Fable 5 拒答基础生物学:AI 安全护栏开始误伤正常知识使用
Anthropic 新发布的 Claude Fable 5 被称为其广泛开放的最强模型,却会拒答细胞膜、线粒体、mRNA 疫苗等基础生物和医学问题。关键不在于模型不会,而在于 Anthropic 为防生物武器风险主动加严护栏;这暴露出前沿模型发布时,安全控制与可用性之间的矛盾正在变得更尖锐。