聚合当前分类下的最新内容,按时间顺序查看第 73 页精选文章。
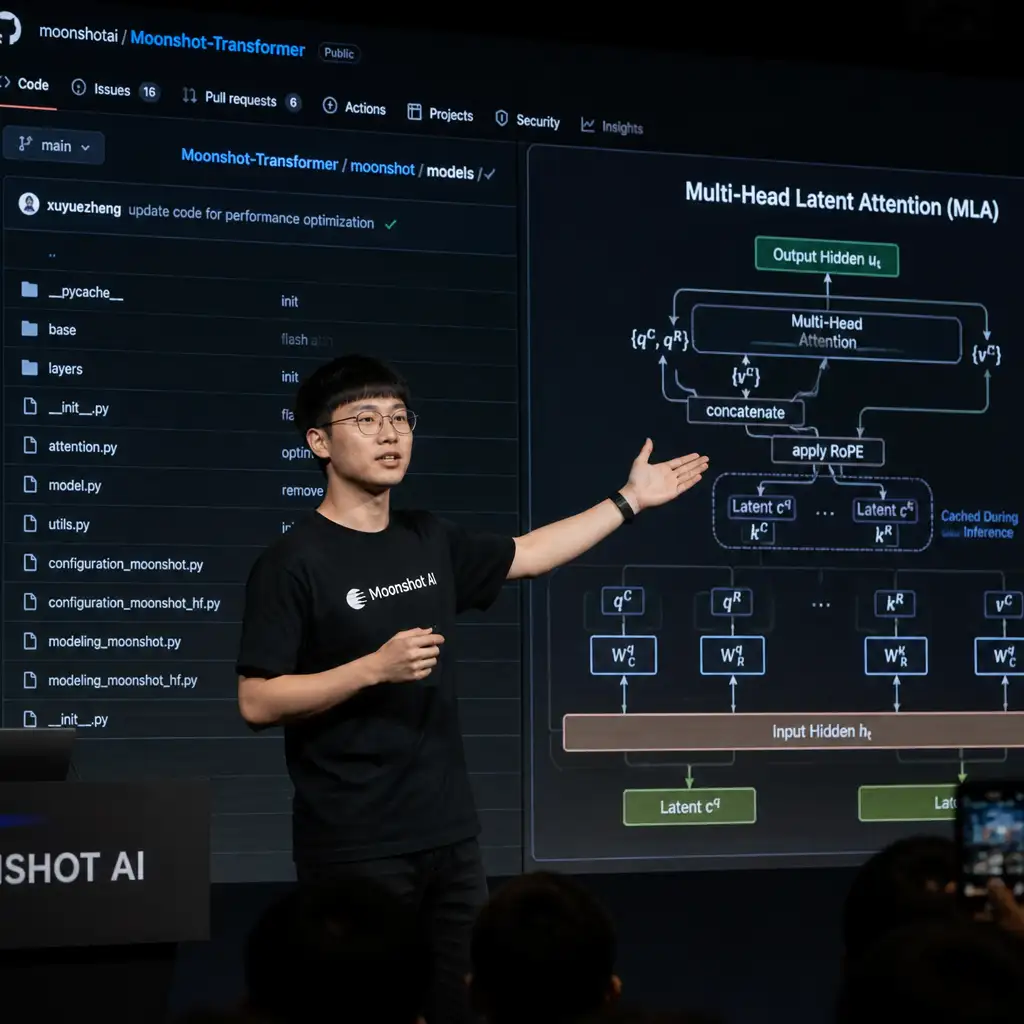
别光看着各家大模型在卷“几百万字”的上下文长度,真正决定它们懂不懂长文的,其实是底层架构的通透度。月之暗面最近在 GitHub 放出的 "Attention-Residuals" 研究,不仅一针见血地指出了大模型“读着读着就失忆”的病根,更向业界秀了一把纯正的极客肌肉:不靠堆算力,靠算法审美来解决问题。