人工智能资讯 第3页
聚合当前分类下的最新内容,按时间顺序查看第 3 页精选文章。

Krea 2 技术报告发布:它赌的不是默认更好看,而是风格探索更宽
Krea 发布 Krea 2 技术报告,重点是图像生成基础模型的数据、训练和控制系统,不是一次产品商业化公告。它的差异化不在宣称单点画质碾压,而在用更宽的数据覆盖、分阶段训练和风格控制,减少模型滑向同一种“精修默认审美”。对 AI 从业者和设计内容团队来说,最该看的不是榜单名次,而是这条路线能不能在真实工作流里稳定交付。

AI 创投的难题:增长是真的,护城河正在变窄
TechCrunch 在洛杉矶 StrictlyVC 活动中采访了 Carter Reum 和 Chang Xu,聊的是 AI 创投最现实的几个问题:怎么定价、怎么避开 OpenAI、Anthropic、Google 这类巨头、哪些赛道还可能有防御性。我的判断是:AI 不是简单泡沫,而是增长曲线、估值假设和竞争边界一起失真。早期创业者和投资人接下来要少看故事,多看摩擦、分发、监管、数据和巨头会不会亲自下场。

Qwen-AgentWorld:阿里争的不是参数,是 Agent 的训练场
阿里 Qwen 团队在 arXiv 发布 Qwen-AgentWorld:两款语言世界模型,用 1000 万条以上真实环境交互轨迹训练,目标是模拟 Agent 交互环境。重点不在“又一个模型”,而在 Agent 训练开始争夺低成本、可控、可扩展的试错场。开发者可以关注,但不宜立刻把真实环境训练全部替换掉,最大风险是评测闭环和环境偏差。

AI 代写不是原罪,把阅读成本甩给同事才是
Josh Moody 批评的不是用不用 AI,而是“自私式 LLM 使用”:用模型省自己的时间,却让同事花更多时间阅读、审阅和追问。最典型的场景是 Slack 长列表、AI 味博客句式、PR 描述和代码评论里的冗长文本。对软件团队来说,真正该管的不是谁用了 AI,而是信息能不能更短、更准、更可审阅。
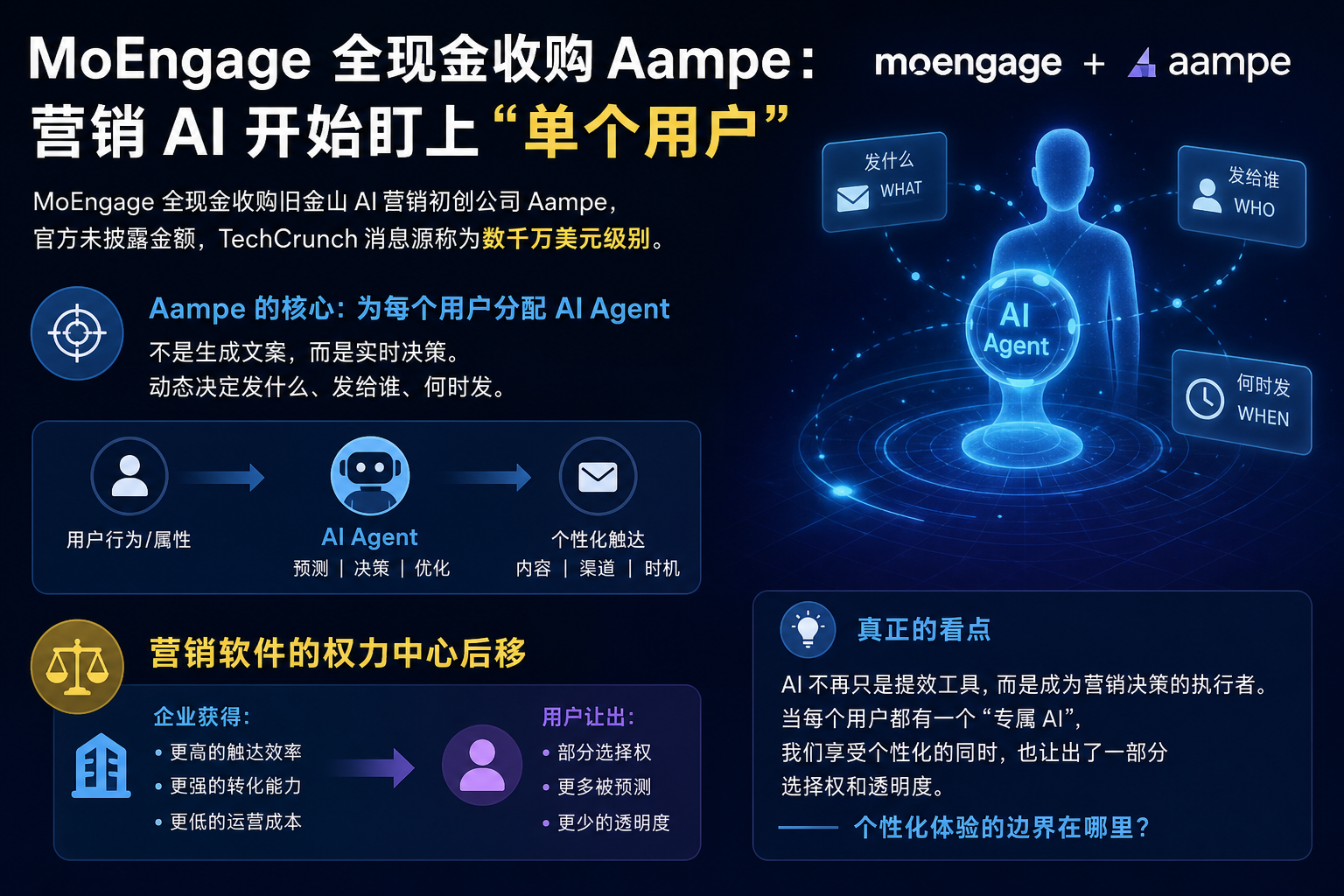
MoEngage 全现金收购 Aampe:营销 AI 开始盯上“单个用户”
MoEngage 全现金收购旧金山 AI 营销初创公司 Aampe,官方未披露金额,TechCrunch 消息源称为数千万美元级别。Aampe 的核心不是生成文案,而是给单个客户分配 AI agent,动态决定发什么、发给谁、何时发。真正的看点是营销软件的权力中心后移:企业拿效率,用户让出一部分选择透明度。

Google Home 摄像头要学会“看背影”,但边界也更难划了
Google Home 自 6 月 23 日起扩展 Familiar Faces:已标记成员在人脸不清晰时,系统可参考体型、衣服颜色等非生物识别信号辅助判断。 人脸库也会自动使用家中成员的最新图像更新,减少旧样本带来的错误通知。 这次更新的重点不只是识别更准,而是家用摄像头正在从看脸走向理解场景,隐私和误判边界会更难处理。

《Artificial》发行遇冷:好莱坞拍 OpenAI,开始不好卖了
亚马逊 MGM 放弃发行《Artificial》后,Netflix、A24、Focus Features、Warner Bros. Clockwork 据称也无意接手,Neon 和 Mubi 仍被传有兴趣。 这部片子后期制作已接近完成,原本据称还有短期冲奥院线、2027 年扩大上映和 SXSW 展映安排,突然失速并不寻常。 更值得看的是:当 AI 巨头同时是投资对象、云服务客户、内容平台伙伴,批判性科技叙事会不会在发行端先被算账。

Superhuman收购GPTZero:AI检测工具越多,答案未必越可信
Superhuman 收购 AI 文本检测初创公司 GPTZero,交易条款未披露。反常点在于,Superhuman 原本已有 AI 检测工具,却仍买下 GPTZero。我的判断是,AI 检测市场接下来拼的不是多一个模型,而是谁能让学校和企业相信检测结果该怎么用、错了谁负责。

斯坦福 HAI 研究:同一 AI 招聘工具,可能把岗位偏差放大成“连续出局”
斯坦福 HAI 披露的真实招聘研究覆盖 340 万人、400 万份申请,样本均由同一第三方 AI 招聘工具评估。研究发现,总体推荐率可能看不出问题,但按具体岗位拆开后,26% 黑人申请者、15% 亚裔申请者投递过对其群体不利的岗位。关键风险不是证明“AI 招聘必然违法”,而是同一供应商被多家雇主复用后,岗位级偏差可能变成跨岗位、跨雇主的机会排除。

FUTO Swipe:一个小模型,动的是手机键盘的隐私入口
FUTO 发布 FUTO Swipe:面向滑行输入的开放模型和 C++ 推理库,已用于离线 Android 键盘 FUTO Keyboard。它的看点不在“又一个输入法模型”,而在端侧运行、数据可复用、训练成本低。限制也要说清:目前高精度 decoder 只有 QWERTY English,模型不是 MIT,推理库是 GPL,商业集成不能想当然。
Claude 隐私政策更新:Anthropic 给年龄与身份核验留出更大空间
Anthropic 发布新版隐私政策,6 月 8 日公布、7 月 8 日生效,明确在特定情况下可要求用户验证年龄或身份。真正要看的不是“Claude 是否全面实名”,而是普通用户输入输出、身份材料和面部几何模板被纳入同一套合规框架后,数据边界变得更宽也更复杂。
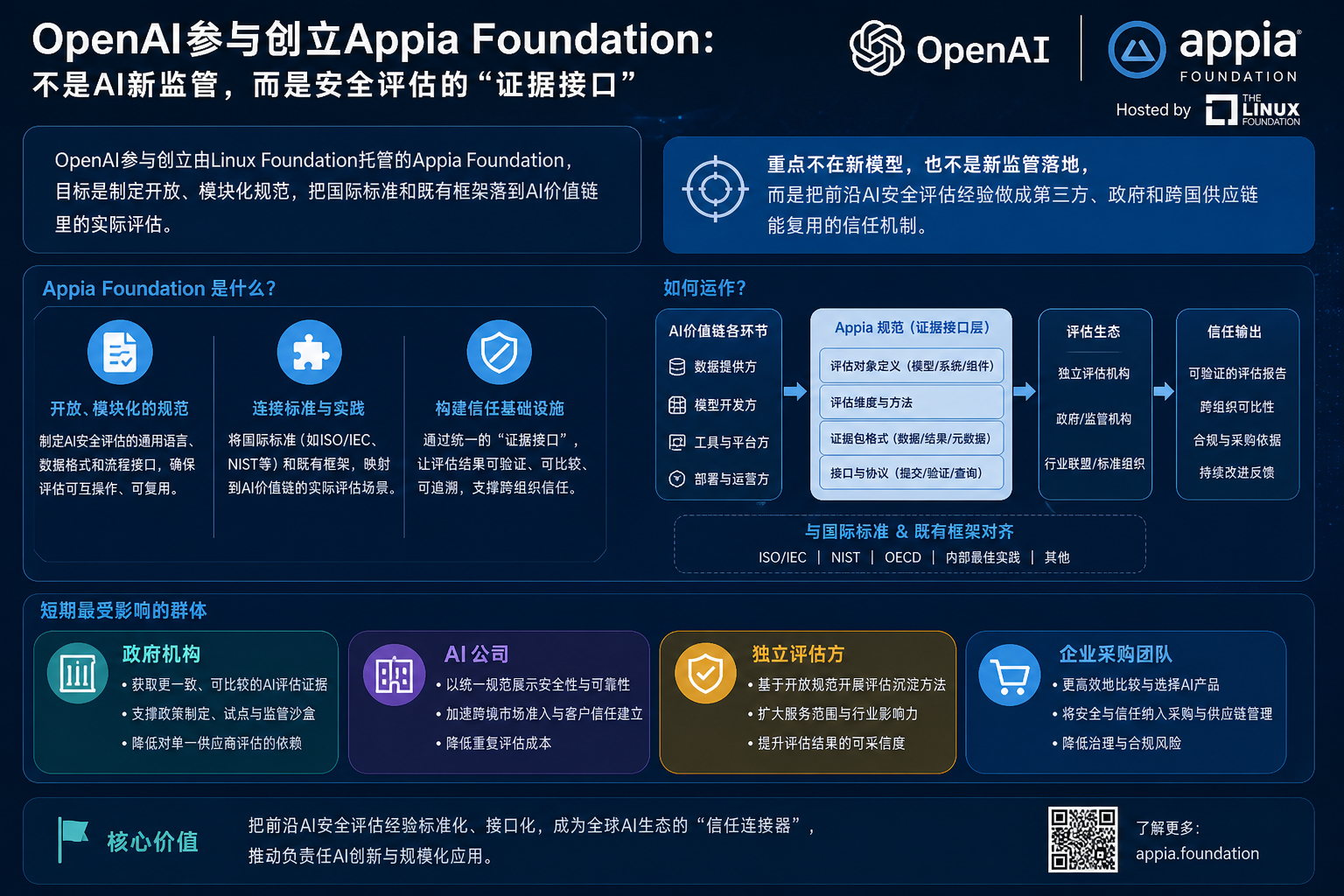
OpenAI参与创立Appia Foundation:不是AI新监管,而是安全评估的“证据接口”
OpenAI参与创立由Linux Foundation托管的Appia Foundation,目标是制定开放、模块化规范,把国际标准和既有框架落到AI价值链里的实际评估。重点不在新模型,也不是新监管落地,而是把前沿AI安全评估经验做成第三方、政府和跨国供应链能复用的信任机制。短期最受影响的是政府机构、AI公司、独立评估方和企业采购团队。

得州Model 3致死事故:特斯拉说司机踩到底,但FSD的账不能只算给司机
得州Katy一辆Model 3高速冲入民宅,造成屋内76岁女性死亡。警方称司机使用了自动驾驶辅助系统,特斯拉AI负责人则称司机把加速踏板踩到100%,手动覆盖了self-driving,撞车时车速达73 mph。现在不能断言FSD导致事故,但特斯拉越把FSD卖成“车会自己开”的期待,事故后的责任边界就越不能只靠一句“司机接管”带过。

浏览器端 AI 的真实麻烦:同一个模型,为什么还要跨站重复下载?
Hugging Face 客座文章用 Transformers.js 演示了一个很具体的问题:同一份 `Xenova/whisper-tiny.en` 和 ONNX Runtime Wasm,在不同 origin 下可能重复下载,示例里多出 177MB 存储。 原因不是浏览器低效,而是现代浏览器为防 timing attack 等隐私泄漏做了缓存分区;Chrome 缓存键包含 Network Isolation Key,不只看 URL。 Cross-Origin Storage API 想用 SHA-256 按内容复用大文件,但它仍是早期 WICG 提案,目前靠 Chrome 扩展 polyfill 实验,不是 Chrome 已上线能力。

GPT-5 Pro解开T细胞旧题?别急着封神,真正变了的是科研分工
OpenAI称,GPT-5 Pro帮助免疫学家Derya Unutmaz重新分析一个搁置三年的T细胞实验,提出脱氧葡萄糖可能通过干扰IL-2蛋白构建,推动T细胞更容易分化为Th17炎症细胞。这个案例的重点不是AI治病,也不是模型已经证明自己理解生物学,而是AI正在进入科研假说生成和实验优先级排序。对AI科研应用读者和生命科学团队来说,真正该看的不是故事多漂亮,而是专家能不能验算、筛选并承担后果。

2783 万美元砸进 NY-12:AI 资本把监管战线前移了
The Verge 引用数据称,科技行业和 AI 相关力量为纽约第 12 国会选区民主党初选投入约 2783 万美元。反常点不在金额大,而在战场小:一个曼哈顿深蓝选区的开放席位,成了 AI 监管影响力的前哨战。现在能判断的不是谁操控了谁,而是科技资本已经开始把政策风险提前投进初选。
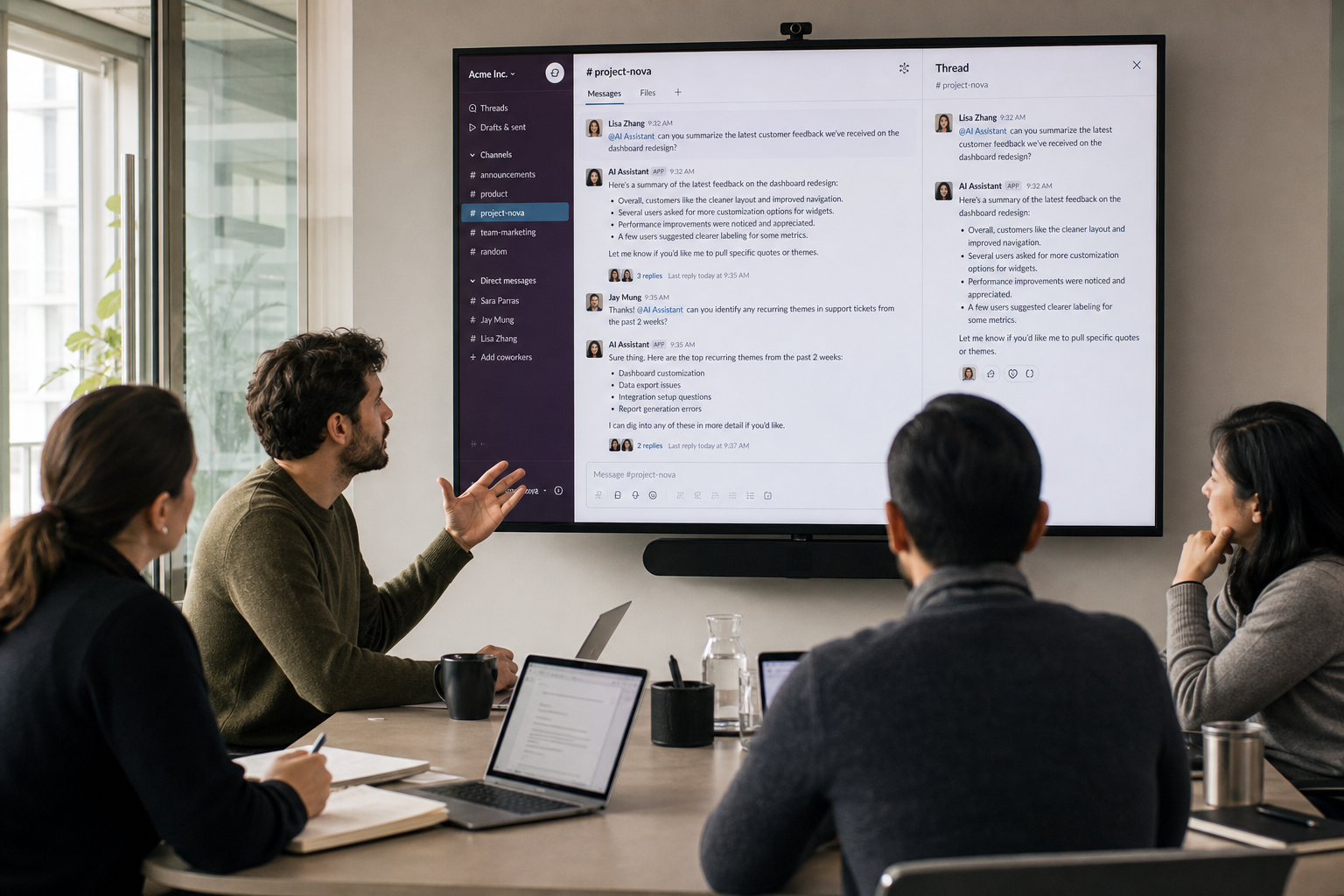
Claude Tag 进 Slack:Anthropic 抢的不是聊天框,是公司记忆
Anthropic 推出 research preview 版 Claude Tag,让 Claude 以常驻同事身份进入 Slack,但目前只面向 Slack 上的 Claude Enterprise 和 Claude Team 客户。 它能被 @ 调用、接任务、记住授权频道上下文,并在线程里公开跟进;关键限制是管理员可控权限,不是无限读取公司 Slack。 真正的看点是企业 AI 的竞争正在转向组织上下文:谁掌握工作现场,谁就更接近下一层入口。
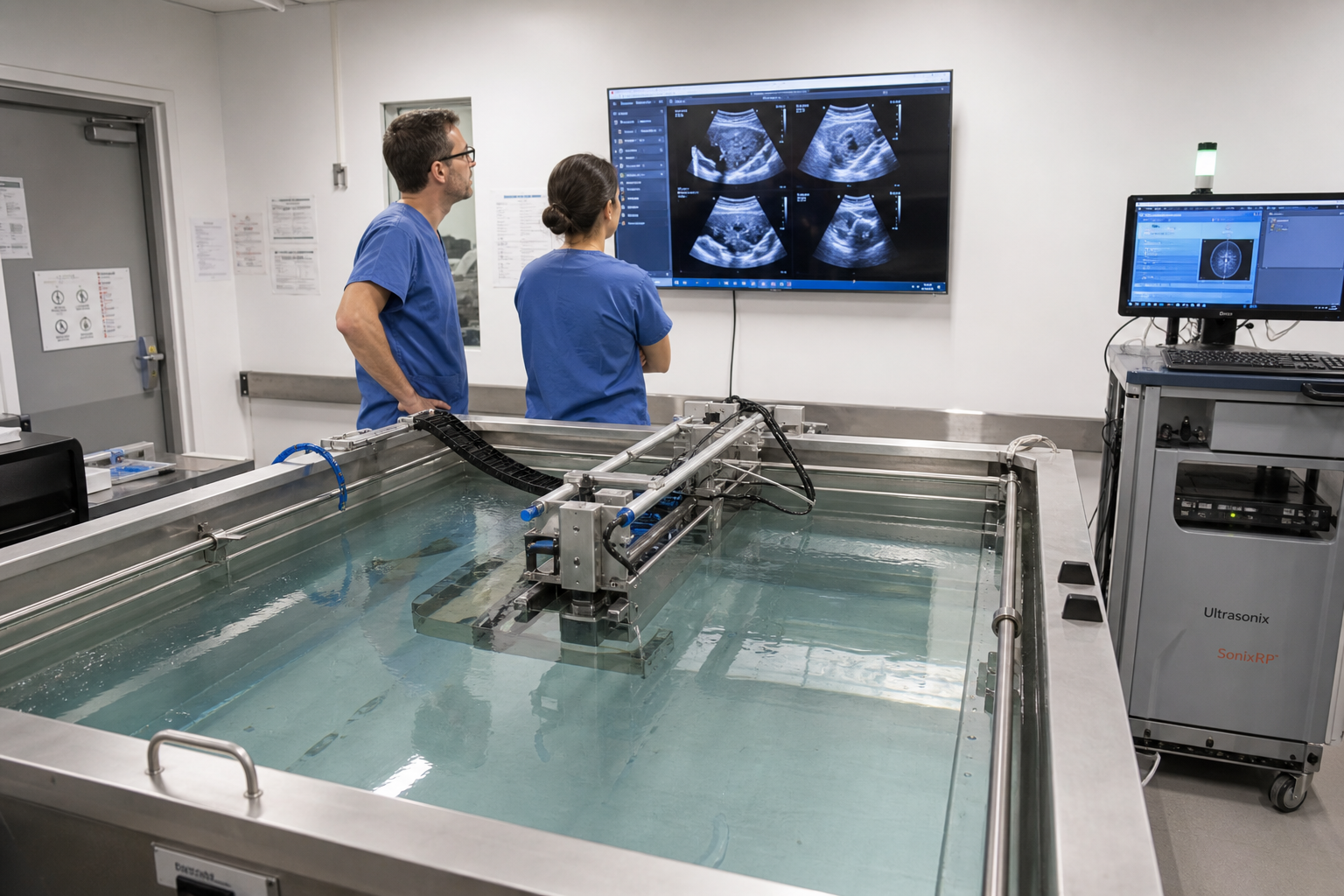
Midjourney想做水槽式全身超声,但医疗AI不能只靠想象力
Midjourney从AI图像生成跨界医疗影像,提出把人置于水中做全身超声扫描,目标是体验像SPA、能力接近MRI。CEO David Holz曾暗示未来可能优于MRI,但目前公开证据还不足以支撑这个承诺。对AI医疗读者和影像从业者来说,这更像一个早期技术叙事,需要看验证、监管和临床采信,而不是按成熟设备理解。
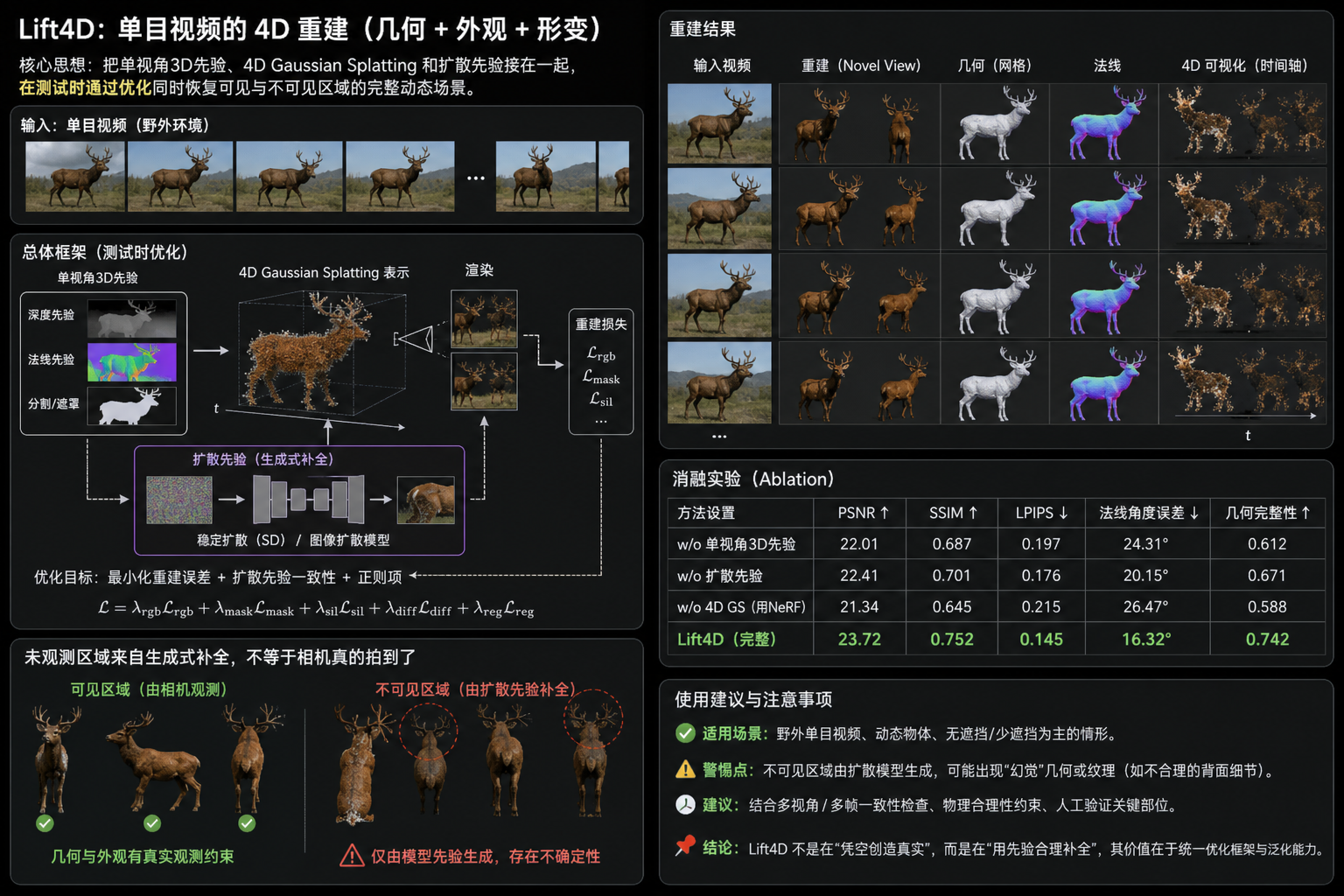
Lift4D做单目4D重建:看不见的背面,开始由扩散模型来补
Lift4D面向野外单目视频,目标是从一个普通视频中重建动态物体的完整几何、外观和形变。它的关键价值不是训练新大模型,而是把单视角3D先验、4D Gaussian Splatting和扩散先验接进同一条测试时优化链路。真正要警惕的是:未观测区域来自生成式补全,不等于相机真的拍到了。

AI 不再便宜:token 账单正在改写企业采购
生成式 AI 正从低价订阅转向按 token 计费,企业开始看到过去被补贴遮住的真实成本。SemiAnalysis 和 Zitron 的数据说明,问题不是没人用 AI,而是很多用法能否承受真实价格。最受影响的是重度企业用户、AI 开发工具团队和正在部署 agent 的公司。

Mistral OCR 4 发布:重点不是多认几个字,而是让文档进入企业 RAG 流水线
Mistral OCR 4 新增 bounding boxes、block types、逐页/逐词置信度和 Markdown 输出,文档不再只是被识别成文本,而是被拆成可定位、可检索、可复核的结构化数据。价格锚点清楚:OCR API 每 1000 页 4 美元,Batch API 2 美元,Document AI 5 美元;基准分数亮眼,但仍应按官方测试和自动评分局限来看。对企业 RAG、搜索和大规模文档处理团队来说,关键动作不是立刻替换旧系统,而是拿自家文档跑一轮验证。