人工智能资讯 第5页
聚合当前分类下的最新内容,按时间顺序查看第 5 页精选文章。
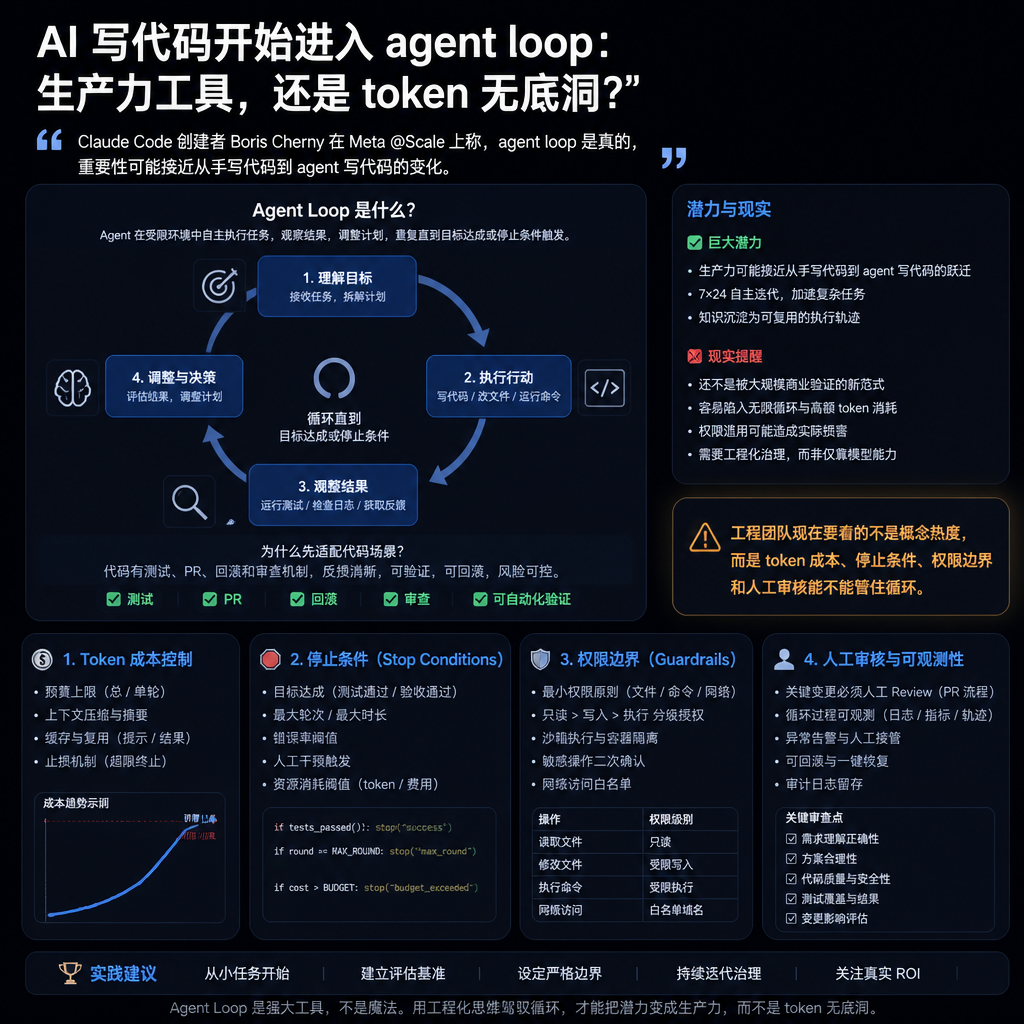
AI 写代码开始进入 agent loop:生产力工具,还是 token 无底洞?
Claude Code 创建者 Boris Cherny 在 Meta @Scale 上称,agent loop 是真的,重要性可能接近从手写代码到 agent 写代码的变化。 它最先适配代码场景,因为代码有测试、PR、回滚和审查机制;但它还不是被大规模商业验证的新范式。 工程团队现在要看的不是概念热度,而是 token 成本、停止条件、权限边界和人工审核能不能管住循环。

AI 修出的纽约租房照,让租客为“不存在的家”多跑一趟
纽约这类高压租房市场里,生成式 AI 和虚拟布置正在把房源照片修得更像“理想之家”。问题不在修图新不新,而在它把租房信息不对称继续推向房东和经纪人一侧。对普通租客来说,代价是更多筛选、核验、通勤和看房成本。

Groq融到6.5亿美元,但它要证明的已经不是芯片了
Groq确认完成6.5亿美元融资,新估值未披露;上一轮估值为69亿美元。半年之前,NVIDIA通过非独家IP授权拿到Groq相关技术使用权,并带走Jonathan Ross、Sunny Madra等核心成员。钱能让Groq继续扩张推理云,但LPU的独占叙事已经松了。

暴雪老工程师求职受挫:AI没毁掉招聘,但放大了最烂的筛选
一名约10年经验、曾在暴雪工作7年的软件工程师,2025年6月随团队被裁后求职受挫,多次进入终面仍落选,还遭遇招聘方后续沉默。真正刺痛他的不是“岗位少”,而是CoderPad、HackerRank、AI监考和简历关键词筛选,把招聘变成低信任消耗战。AI没有发明烂招聘,但让作弊更容易、筛选更便宜,守规则的人反而更吃亏。

DeepMind 投资 A24:AI 进好莱坞,先过创作者这一关
据《华尔街日报》报道,Google DeepMind 将向 A24 投资 7500 万美元,双方合作开发电影制作 AI 工具。 这不是收购,也不是 A24 全面用 AI 拍片,关键在于 DeepMind 想让一线艺术家参与工具打磨。 对 AI 产业和影视从业者来说,接下来要看的不是演示片多惊艳,而是版权、工会、素材归属和片场流程能不能谈拢。

Alexa+ 在印度测印地语:亚马逊想补的不是语言包
亚马逊已向部分印度用户发邮件,邀请他们在 6 月 22 日前填写印地语表单,加入 Alexa+ Beta 测试。Alexa+ 目前尚未在印度正式上线,发布时间不明,测试版也可能出现错误、信息不准确和本地发音问题。真正要看的,是亚马逊能否把生成式语音助手从英语市场带进高人口、多语言、语音优先的印度场景。

Google投A24:AI电影工具要的不是片库,是片场入场券
WSJ报道称,Google将向A24投资约7500万美元,并通过DeepMind展开多年AI研发合作;这是Google首次入股电影公司。合作据称非独家、不开放A24片库数据,也没有公布具体电影项目。真正要看的不是AI能不能生成画面,而是谁来定义电影制作、发行和创作控制的新工作流。

Reflection 每月 1.5 亿美元租 SpaceX 算力:开源 AI 也开始交重资产入场费
Reflection AI 将从 2026 年 7 月 1 日起,每月向 SpaceX 支付 1.5 亿美元,租用孟菲斯附近 Colossus 2 数据中心的 Nvidia GB300 芯片及配套硬件。合同最高约 63 亿美元,但前三个月后双方可提前 90 天通知终止,不能直接当成 SpaceX 的确定收入。我的判断是:这单证明开放权重模型也被卷进了前沿 AI 的算力军备赛,SpaceX 则把马斯克系 AI 基础设施变成了更稳的出租生意。

GLM-5.2 刺到闭源模型的,不是榜单,是编码工作流
Z.ai 在 6 月 16 日公开 GLM-5.2 的 MIT 许可权重,社区反馈显示,它在部分编码代理、设计和 agent 场景里已接近甚至挑战 Claude/OpenAI 前沿模型。 更关键的是,它开始进入 Claude Code 这类真实工作流,而不是只在 benchmark 上好看。 对开发团队和企业采购来说,这会带来一个现实动作:先别急着锁死闭源高价套餐,开源代理模型已经值得纳入评估。

密歇根小镇反对核武 AI 数据中心:算力落地,谁有权说不
密歇根 Ypsilanti Township 正在阻击密歇根大学与洛斯阿拉莫斯国家实验室拟建的大型 AI 数据中心,项目用途包括美国核武器研发模拟。居民和镇委员会担心的不是抽象的 AI,而是水、电、噪音、环境影响,以及地方同意权被绕开。真正的分歧在于:州政府、大学和国家实验室拿走算力叙事时,地方社区是否只能接住账单。

Moebius 0.22B 对标 10B:小模型这次打中的是图像修复成本
华科与 vivo AI Lab 发布 Moebius,论文/项目页称这个 0.22B 图像修复模型,在 Places2、CelebA-HQ、FFHQ 等基准上可对标 FLUX.1-Fill-Dev、SD3.5 Large-Inpainting。真正要看的不是“小模型赢了大模型”,而是窄任务里能不能用蒸馏和结构设计,把 10B 级模型的交付成本打下来。对移动端修图、本地影像编辑和边缘设备团队,接下来最该盯的是评测可信度、真实推理耗时和部署边界。

Claude Code 的“扩展思考”,别当成完整审计记录
Claude Code 会把会话记录到本地,但 thinking block 里可见的主要是约 600 字符的 signature,而不是明文推理。 Anthropic 文档说明,extended thinking 返回的是完整思考过程的 summary;推理内容被加密,密钥不在用户机器上。 对做代理、自动化工作流和合规审计的团队来说,问题不是“有没有记录”,而是这份记录能不能当证据。

Anthropic 新模型被美国限制:安全叙事会变成出口管制依据吗
美国上周禁止外国人使用 Anthropic 最新模型 Mythos 和 Fable,但目前没有证据显示禁令由 Anthropic 自己的表述直接触发。 更稳妥的判断是:Anthropic 长期强调 AI 风险,让它的话语更容易被美国国家安全框架吸收。 真正要受影响的,是跨国 AI 团队、欧洲企业客户,以及依赖美国前沿模型做安全研究的人。

Import AI 462:AI 逼近的三种权力,不只是变聪明
Import AI 462 汇总了三条前沿议题:AI 文本劝服稳定超过专家人类,自我维持 AI 的关键落到机器人和工业链,DeepMind 梳理 AGI 走向 ASI 的几条路径。最该看的不是模型又强了多少,而是 AI 正在靠近三种权力:影响人、减少对人的依赖、超越人类组织。短期最现实的变量,是谁能大规模调用这些能力,以及监管、平台和开发团队如何限制滥用。

PP-OCRv6 上 Hugging Face:VLM 很热,但 OCR 还得小模型交结果
百度飞桨 PaddleOCR 在 Hugging Face 发布 PP-OCRv6,提供 1.5M、7.7M、34.5M 三档模型,small 和 medium 支持 50 种语言。官方基准里,medium 检测 Hmean 86.2%、识别准确率 83.2%,相比 PP-OCRv5_server 分别提升 4.6 和 5.1 个百分点。我的判断:VLM 适合做理解,小模型 OCR 适合交付稳定、低成本、可部署的文字结果。
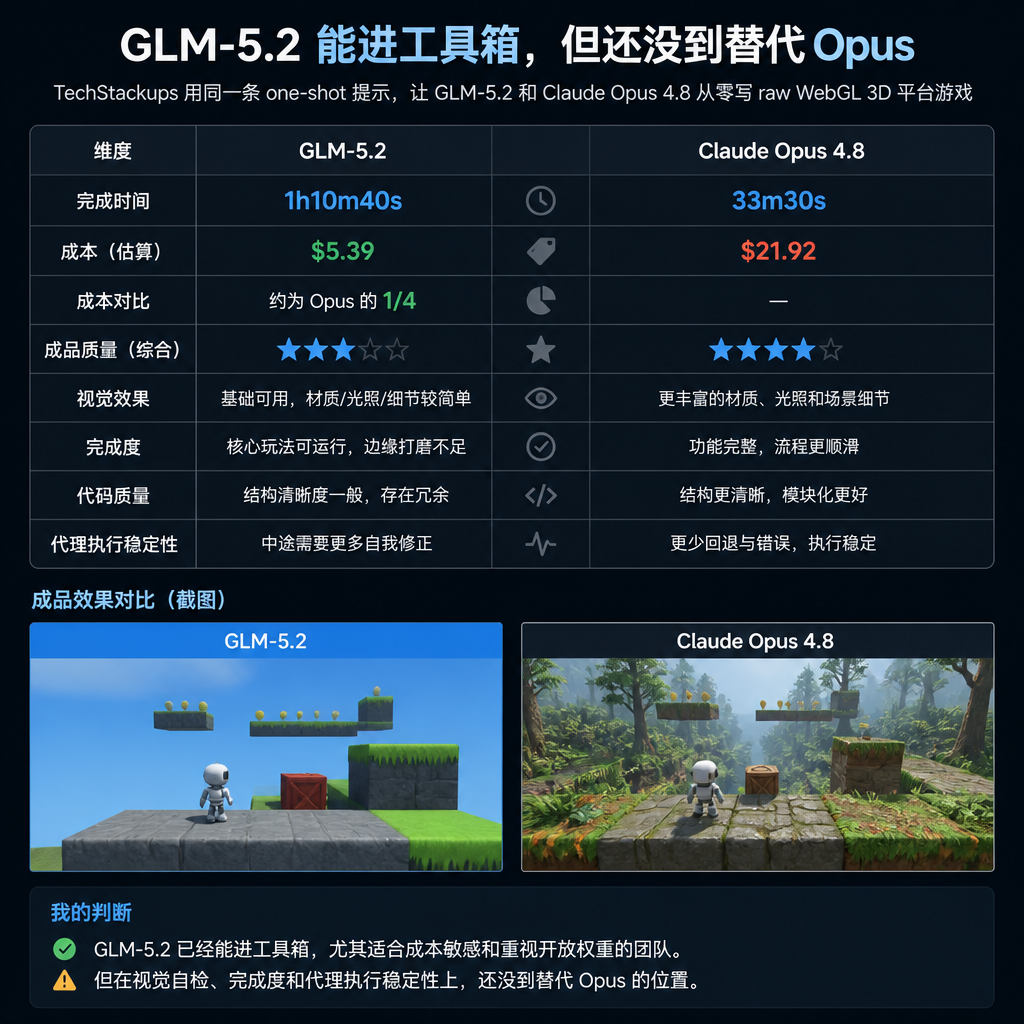
GLM-5.2 能进工具箱,但还没到替代 Opus
TechStackups 用同一条 one-shot 提示,让 GLM-5.2 和 Claude Opus 4.8 从零写 raw WebGL 3D 平台游戏;Opus 用 33m30s 完成,GLM-5.2 用 1h10m40s。GLM-5.2 成本只有 5.39 美元,约为 Opus 估算成本 21.92 美元的四分之一,但成品缺陷更基础。我的判断:GLM-5.2 已经能进工具箱,尤其适合成本敏感和重视开放权重的团队;但在视觉自检、完成度和代理执行稳定性上,还没到替代 Opus 的位置。

Claude 要验身份,开放权重模型的账重新算了
Andrew Marble 因 Claude 身份验证机制,重新评估是否放弃 Claude/GPT 等闭源顶级模型,转向开放权重模型。重点不是开放模型已经全面追平,而是专业用户开始把平台控制、合规解释和迁移成本放进同一张账单。对开发者和技术团队来说,问题正在从“哪个模型最强”变成“我能不能承受工具被平台继续加码控制”。

Sakana AI 的 Fugu:不是新大模型,而是把大模型变成可调度供应链
Sakana AI 发布 Fugu,把多个顶级模型动态编排成一个 OpenAI 兼容 API,而不是推出单一基础模型。更关键的变化是:企业可以按任务调度、排除特定模型或供应商,降低单一厂商绑定。官方跑分很强,但部分基线来自 provider-reported scores,真实生产里的成本、稳定性和合规责任还要另算。

AI 末日论,正在替估值打工
George Hotz 在博客里批评伯克利和旧金山 AI 圈的末日叙事,尤其不满 Anthropic 式的政策恐慌、指数增长和递归自我改进话术。 他的核心判断很刺耳:当前技术成果不足以支撑估值,于是公司需要用未来灾难和未来价值制造心理压力。 这篇文章要看的不是 AI 会不会毁灭世界,而是末日论是否正在变成融资、游说和注意力机器的一部分。
医生改口后,低价全身超声真正要算的账变了
Matthew Zirwas 修正了自己对 Midjourney 低价全身超声筛查的判断:如果设备真能高分辨率、低成本、无害且方便复查,传统筛查的收益/伤害比需要重算。关键不是“早发现一定救命”,而是发现异常后,能不能用连续观察替代一部分活检和切除。普通用户现在不该把它当救命神器,更该盯住后续数据、随访规则和总成本。

Meta 员工请愿反对用电脑使用数据训练 AI:MCI 争议卡在有效同意
Meta 员工请愿要求 Mark Zuckerberg 和公司领导层承诺,不收集员工 computer-use data 用于 AI/ML 模型训练,矛头指向内部项目 MCI。 这件事目前不能写成 Meta 已确认全面监控员工电脑;真正的争议是,雇主能否把键盘、鼠标、屏幕交互这类工作过程数据拿去训练模型。 对准备训练 AI agent 的企业来说,最现实的动作是先停下采集方案,补齐隐私审查、员工数据审查和可拒绝机制。