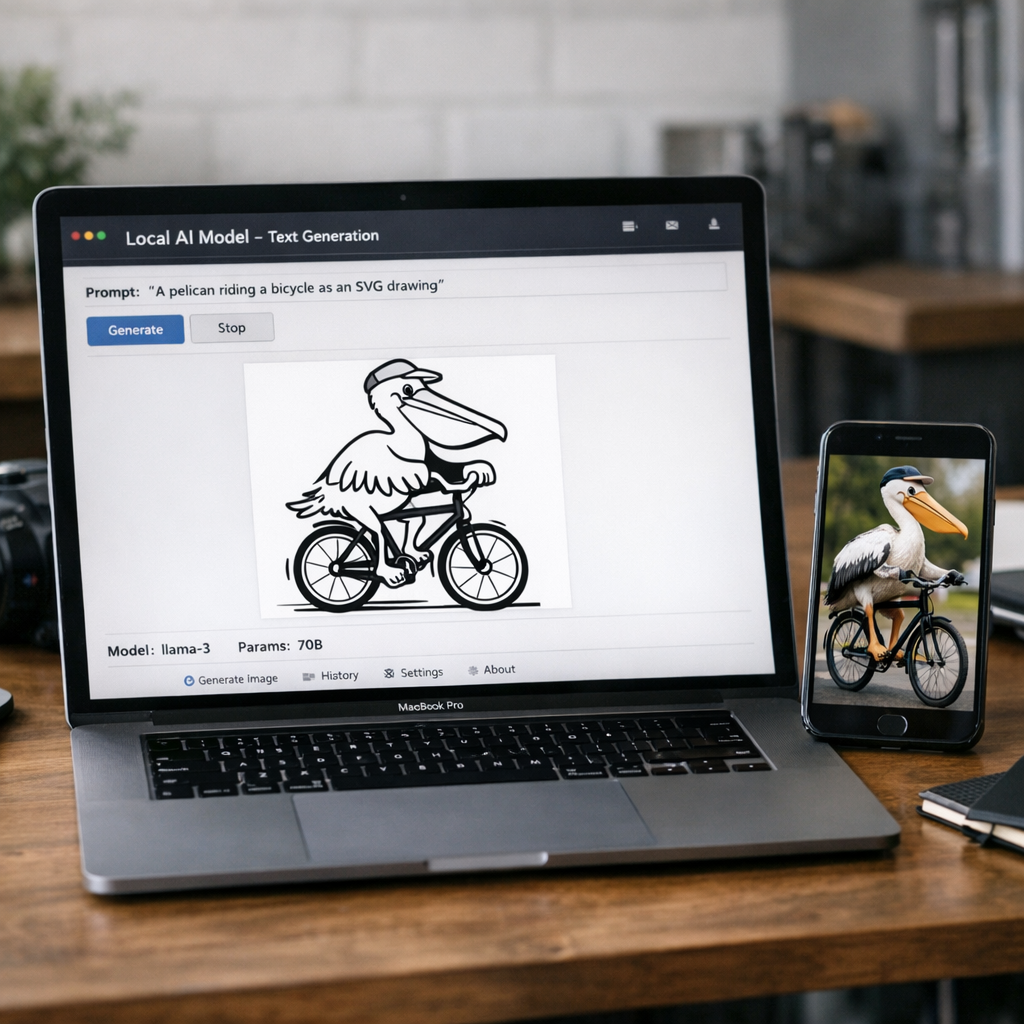
阿里最新模型 Qwen3.6-35B-A3B,在一台 MacBook Pro M5 上跑的 20.9GB 量化版本,靠本地推理生成的 SVG“骑自行车的鹈鹕”,被独立开发者 Simon Willison 判定优于 Anthropic 新发布的 Claude Opus 4.7。连他自己都承认,这个测试原本是个玩笑,但这次结果仍然刺中了当下大模型竞争里最不舒服的一点:昂贵的闭源旗舰,并不总能在具体任务上压过可本地运行的开源模型。
这件事重要,是因为它揭开了一个越来越现实的趋势:模型能力正在分裂。你很难再用一张排行榜、一个总分,或者一句“这个模型更聪明”来覆盖所有使用场景。这件事没那么重要的地方也很清楚——没有人会因为一张鹈鹕图,就认定 Qwen 比 Opus 4.7 整体更强,企业采购更不会据此改预算。但对开发者和个人用户来说,这类边缘任务的胜负,往往直接决定“我今天到底用谁”。
一次玩笑测试,打中了模型比较的软肋
Willison 测试的是文本生成 SVG 插画能力。Qwen 使用的是 Unsloth 发布的 Qwen3.6-35B-A3B-UD-Q4_K_S.gguf 量化文件,大小 20.9GB,通过 LM Studio 在本地运行;Claude Opus 4.7 则是 Anthropic 的最新闭源旗舰,连 thinking_level: max 都试了,结果自行车车架结构还是画歪了。
他随后又拿出一个“备份题”——“生成一只骑独轮车的火烈鸟 SVG”。Qwen 再次赢下,甚至在代码注释里写了 <!-- Sunglasses on flamingo! --> 这种颇有设计感的小细节。这里最刺眼的对照,不是审美,而是成本和部署方式:一个在笔记本本地跑的量化模型,在狭窄但真实的任务上,压过了云端闭源大模型。
这不等于 Qwen 整体强于 Opus 4.7,但足以说明:模型“总能力”与“任务命中率”正在脱钩。
真正该看的,不是鹈鹕,而是本地模型的门槛在继续下降
过去一年,本地模型进步很快。2024 年不少本地 LLM 还停留在“能跑起来”,到了 2026 年,35B 级别的混合架构模型已经能压缩到 20GB 出头,在消费级高端笔记本上完成相当体面的生成任务。Willison 提到,2024 年 10 月那些早期“鹈鹕”作品几乎都是垃圾图;到了 2026 年,Gemini 3.1 Pro 已经能画出可用插图,Qwen 则把这件事推进到了“本地可用”。
这背后有个读者不一定会立刻注意到的限制条件:Qwen 这次赢,依赖的是量化、GGUF 格式、LM Studio 这套本地工具链成熟,而不是单纯模型参数更大。也就是说,今天让本地模型更有竞争力的,不只是阿里训练出了新模型,还包括 Unsloth 这类社区团队把模型压缩、封装、适配到普通机器能用的程度。行业现实是,开源模型的战斗力,越来越来自“模型 + 工具链 + 分发”的组合,而不是实验室单点突破。
对谁有影响,影响到什么动作
如果把这件事放回真实使用场景,受影响的人其实很具体:
| 人群 | 眼前变化 | 更现实的动作 |
|---|---|---|
| 独立开发者 | 本地模型可承担更多小任务 | 先用 Qwen、Llama 之类本地模型做原型,再决定是否调用云 API |
| 设计与前端工程师 | SVG、图标、草图类生成更适合多模型试跑 | 工具链会从“固定一家 API”变成“本地+云端混用” |
| 企业采购与平台团队 | 不会因这次结果立刻换主模型 | 但会要求供应商补充更细的任务级评测,而不是只给总榜成绩 |
| 闭源模型厂商 | 品牌旗舰不再天然等于每个子任务最优 | 会继续强化特定工作流、企业集成和安全卖点 |
对普通用户来说,最直观的变化不是“谁更聪明”,而是“有没有必要每次都把请求发到云端”。如果你的任务是生成图标、流程草图、页面插画、简单代码片段,本地模型一旦足够好,隐私、延迟和成本都会变成实打实的优势。相反,涉及长链推理、复杂文档理解、企业知识库协作,Opus 这类闭源旗舰仍大概率更稳。
这个结果也有边界,别把玩笑题当成总榜
Willison 自己已经说得很清楚:他不相信 Qwen 的 21GB 量化版会比 Anthropic 最新旗舰“更强或更有用”。这个判断我同意。SVG 生成这种任务,受提示词风格、模型训练语料、输出格式偏好影响很大,偶然性比通用问答、编程代理、复杂推理更高。
还有一个容易被忽略的变量:闭源模型厂商常常把优化重点放在高价值场景,比如企业自动化、长上下文、代理执行、代码审查,而不是“生成一只结构正确的骑车鹈鹕”。Anthropic 在 2025 年后明显把 Claude 的定位推向工作场景和安全可控性,这会影响模型在一些“边缘创意任务”上的调校优先级。换句话说,Qwen 赢的是一个具体切片,不是整个战场。
但这个切片依然有价值。它提醒行业,评测越来越需要拆开看:
- 文本推理强,不代表图形生成细节强
- 总榜领先,不代表本地替代不可行
- 闭源旗舰贵,不代表每个细分任务都更值
如果接下来更多开发者开始用这类“小而怪”的真实任务来选模型,大模型竞争会从“谁是第一”变成“哪一个最适合这项工作”。这比排行榜更麻烦,但也更接近现实。