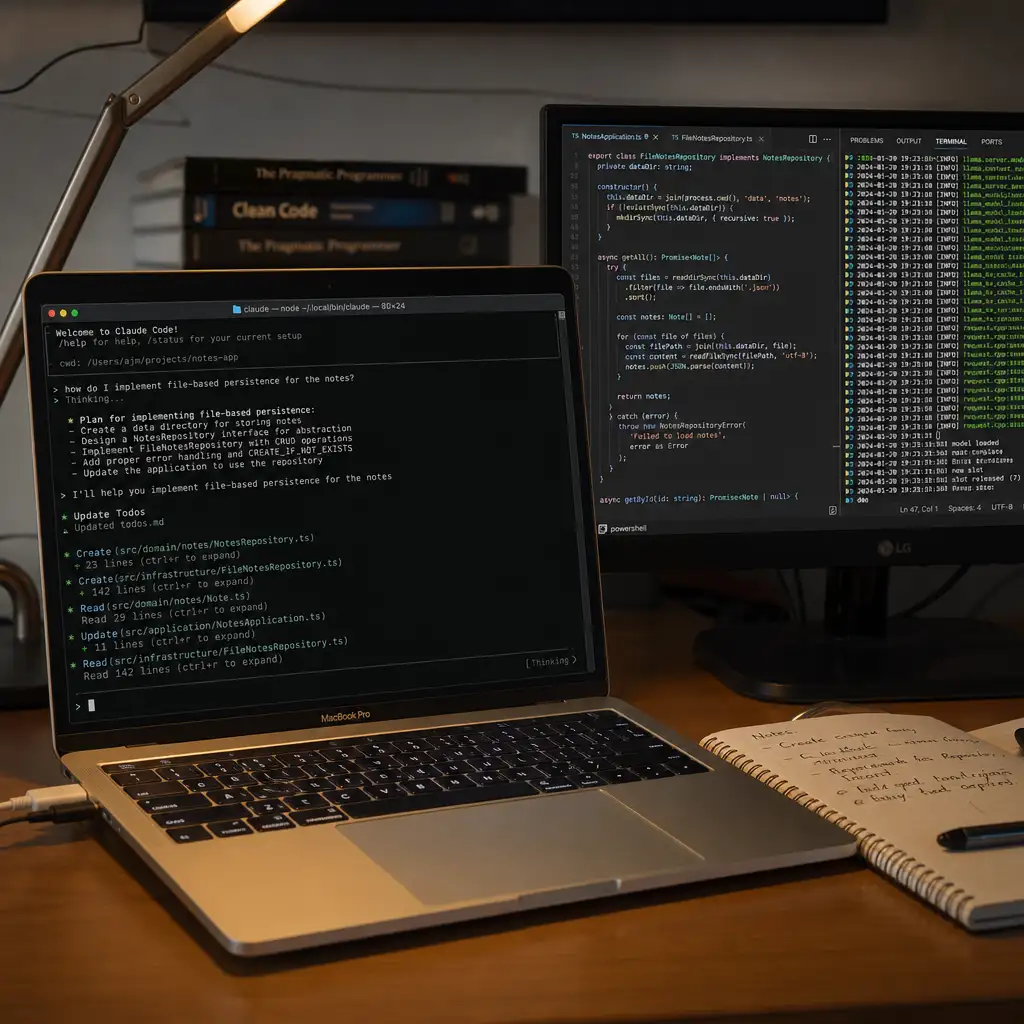
一台 Apple M1 Max、64GB 统一内存、macOS 15.7.7 的 Mac,跑出了一个可离线使用的本地编程代理。
底层是 llama.cpp 的 Metal/Accelerate。主模型是 Gemma 4 26B-A4B Q4,配 Q8 MTP 草稿模型和 mmproj-BF16 投影器。终端代理接 Pi,通过 OpenAI 兼容接口调用本地服务。
这件事有意思的地方,不是“Mac 又能本地跑大模型了”。真正值得看的是:在本地编程代理这个具体场景里,llama.cpp + Metal + Gemma 4 MTP,是否比 MLX 或纯主模型更实用。
我的判断是:在这位开发者的环境和测试模型里,答案偏向“是”。但 72.2 tok/s 不能被当成所有 Mac 的通用结论。
速度:MTP 有用,但别把 1.24 倍说成翻倍
作者用的测试提示很具体:让模型写一个解析 unified diff 的 Python 函数,并解释两个边界情况。每次生成约 128 个 token。
在这台 M1 Max 上,纯 Gemma 4 26B-A4B Q4 通过 llama.cpp Metal 生成速度是 58.2 tok/s。加入 Q8 MTP 草稿模型后,最高到 72.2 tok/s。
| 方案 | 生成速度 | 该怎么理解 |
|---|---|---|
| llama.cpp Metal,纯主模型 | 58.2 tok/s | 已经可用,但代理多轮调用会显得慢 |
| llama.cpp Metal + Q8 MTP | 72.2 tok/s | 约 1.24 倍提升,体感更顺 |
| MLX-LM,文中几组 4-bit 检查点 | 38.1-45.8 tok/s | 仅在该环境和这些检查点下落后 |
| Qwen3.6 35B-A3B + MTP | 约 55 tok/s | 可能更强,但等待成本更高 |
这里最容易被误读的是 MTP。
MTP 不是一个按下就翻倍的开关。作者扫了 --spec-draft-n-max 从 1 到 6 的参数。结果是,3 在这台机器上最快,2 很接近,5 和 6 反而变慢。
这说明一个现实问题:本地代理要快,不只看主模型。草稿模型质量、接受率、量化方式、Metal 调度和具体硬件都会影响结果。调参不是锦上添花,是能不能跑顺的关键变量。
对使用 Mac 本地跑大模型的开发者来说,这个结果更像一个路线提示:如果你已经在 M 系列 Mac 上折腾本地模型,可以优先试 llama.cpp Metal + MTP,而不是只盯着 MLX。但别直接拿 72.2 tok/s 规划团队体验,它只是这台 M1 Max 的实测点。
可用性:OpenAI 兼容和截图输入,比跑分更关键
本地编程代理以前最常见的尴尬是:模型能跑,但工具链接不上;能聊天,但看不到项目现场。
这套方案绕过了一部分问题。作者用 llama-server 暴露 OpenAI 兼容端点:
http://127.0.0.1:8080/v1
这样 Pi 可以像调用云端模型一样调用本地模型。对编程代理来说,这比单纯命令行聊天有用得多。
最小可复现配置大致是这几块:
| 模块 | 配置要点 |
|---|---|
| 主模型 | gemma-4-26B-A4B-it-UD-Q4_K_XL.gguf |
| MTP 草稿模型 | MTP/gemma-4-26B-A4B-it-Q8_0-MTP.gguf |
| 图片投影器 | mmproj-BF16.gguf |
| llama-server 核心参数 | --model-draft、--spec-type draft-mtp、--spec-draft-n-max 3、--mmproj、-ngl 999、-fa on、-c 65536 |
| OpenAI 兼容端点 | http://127.0.0.1:8080/v1 |
| Pi 输入配置 | input 需要写成 ["text", "image"] |
有一个限制必须讲清楚:不要把 Gemma 4 26B-A4B 直接理解成原生多模态模型。
文中图片输入依赖的是 mmproj-BF16.gguf 投影器。Pi 里还要把 input 配成 ["text", "image"]。否则截图不会被正确送进模型链路。
这对想搭建离线编程代理的工程师很直接:如果你的需求只是本地补全和问答,纯文本链路就够了;如果你想把报错截图、界面截图、代码片段截图交给代理看,mmproj 和 Pi 的输入配置不能省。
这也是本地方案和云端代理的分水岭。云端产品把这些封装好了。本地方案把控制权给你,也把脏活留给你。
该谁用:Mac 开发者可以试,团队迁移要慢一点
这套栈最适合两类人。
一类是已经在 Mac 上本地跑大模型的开发者。对他们来说,动作很明确:可以把 llama.cpp Metal + Gemma 4 MTP 放进优先测试列表,重点测 --spec-draft-n-max 2/3,不要一上来追更大的草稿步数。
另一类是想搭离线编程代理的工程师。尤其是弱网、内网、隐私敏感环境下,本地代理的价值会被放大。断网时还能跑,代码和截图留在本机,OpenAI 兼容接口还能接现有工具链。
但团队级迁移不该太快。
现在能看到的代价也很清楚:模型目录大约 17GB,长上下文会带来内存压力,不同模型格式之间可能有兼容问题,本地小模型在复杂工程任务上也有能力上限。
Qwen3.6 35B-A3B 是一个很好的对照。它可能更强,但作者实测约 55 tok/s,低于 Gemma 4 + MTP 的 72.2 tok/s。对编程代理来说,慢不是纸面数字。多轮工具调用、改错、再生成,每一步都在消耗耐心。
所以更现实的做法是:个人开发者可以先把云端代理作为主力、本地代理作为断网和隐私场景的备份;小团队可以先做灰度,不急着采购新硬件,也不急着把云端额度全砍掉。
接下来真正要看三件事。
| 观察点 | 为什么重要 |
|---|---|
| llama.cpp 的 MTP 接受率和稳定性 | 决定 72 tok/s 这类结果能否更稳定地出现 |
| MLX 对 Gemma 4 MTP 的兼容进展 | 决定 Mac 原生路线能不能追回性能差距 |
| Pi、Aider、Continue 等工具的本地多模态配置 | 决定普通工程师是否还要手写一堆 JSON |
这篇实测至少表明一件事:Mac 本地编程代理已经不是玩具状态。但它还没到“装上就能替代云端代理”的程度。
边界很清楚。能跑,能接工具,能看截图;也要调参数、吃内存、忍受模型能力差距。知止不殆。