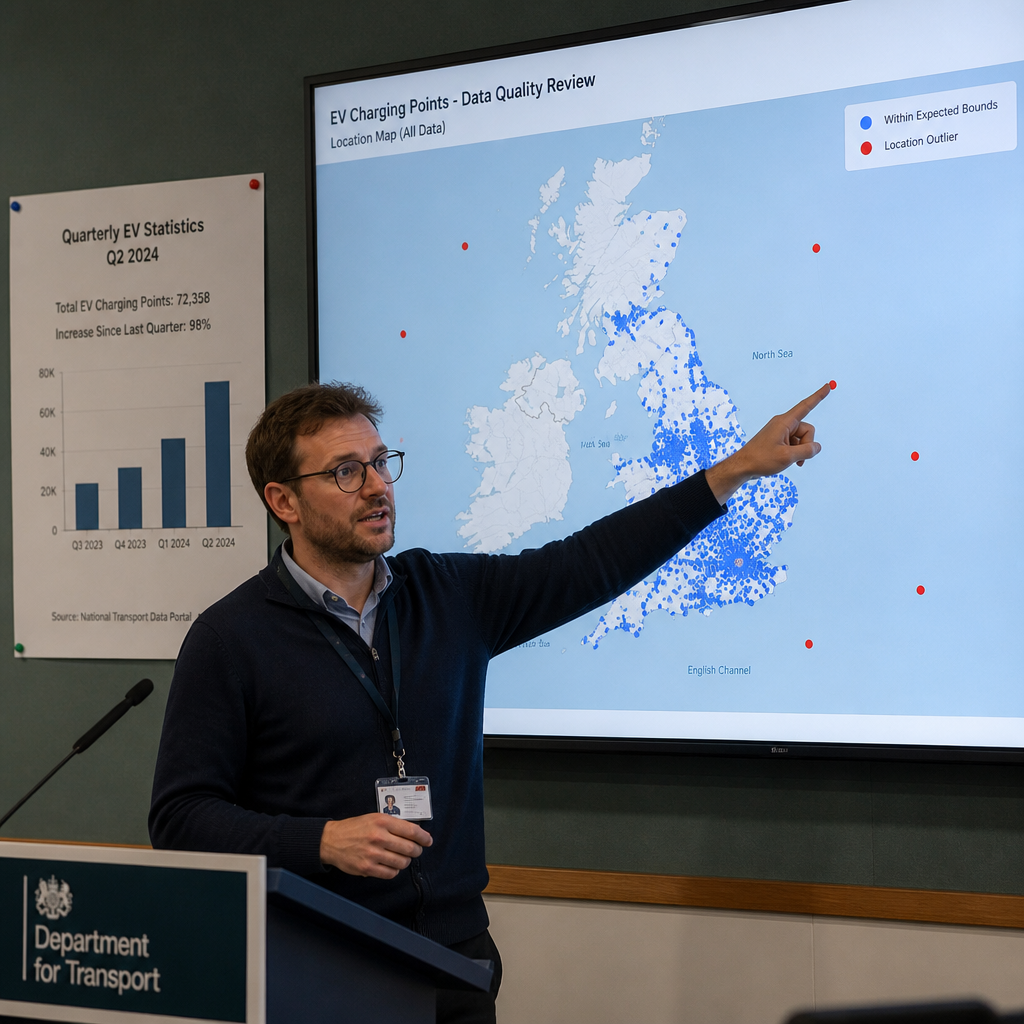
如果你打开一份政府公开数据,发现英国的加油站有几家开在印度洋里,第一反应大概不是愤怒,而是想笑。笑完之后,才会有点发冷:这玩意儿竟然是真的,而且是公开发布、面向社会使用的数据。
3 月底,软件开发者 Andy Brice 在自己的博客上发文,火力很直接——“别再发布垃圾数据了,这太丢人”。他点名了两件事:一是英国政府的燃油价格查询数据存在明显错误,二是英国汽车服务机构 RAC 一份关于电动车的报告图表出现了肉眼可见的数量级失真。这篇文章之所以值得拿出来说,不在于它揭出了什么惊天黑幕,而在于它揭开了一个科技行业、公共部门甚至 AI 时代都越来越常见的尴尬现实:很多人正在把“数据”当作一种装饰,而不是一种需要被认真对待的基础设施。
加油站开进海里,问题不只是填错经纬度
Andy Brice 最先发现的问题,出在英国政府提供的一份燃油价格 CSV 数据集上。这份数据本来很有现实意义:它汇总了英国各地加油站的位置和油价,在国际油价波动、地缘冲突频繁的当下,这类数据不只是给消费者省几镑那么简单,也会被媒体、研究者、创业公司和各类导航服务拿去做二次分析。
但 Brice 只是快速看了一眼,就发现经纬度图上冒出几个极其扎眼的离群点。进一步排查后,一些“英国加油站”赫然出现在印度洋和南大西洋。至少有一处错误很像是经纬度字段填反了——这属于任何有地图可视化经验的人,几分钟内都能揪出来的问题。更夸张的是油价字段,最高和最低单价之间的比例竟然达到 1538:1。你很难把这理解为市场波动,只能理解为录入事故。
这类错误的来源其实不难猜。很可能是各家加油站自行提交数据,人工录入时把字段填错、单位搞混、少打了小数点。人会犯错,本来不稀奇。真正的问题在后半段:政府作为汇总和发布方,竟然几乎没有做最基本的校验。经纬度是否落在英国边界附近、油价是否在合理区间、字段格式是否一致,这些都不需要什么高深 AI,更不需要大模型,写几条规则就能拦住一大半问题。
Brice 说自己 3 月 22 日就向相关部门报告了问题,对方 24 日回邮件表示“已转交技术团队查看”,但 29 日发布的新 CSV 仍然带着这些垃圾数据上线。这个细节比错误本身更刺眼:它说明某些机构已经默认“数据有点脏也能发”,把公众可用性放在了流程后面,把流程完成当成了工作完成。
一张错误图表,足以让一份报告失去公信力
第二个案例来自 RAC 的一份电动车报告。问题出在第一张图表:2024 年英国道路上的纯电汽车数量大约还是 140 万辆,到了 2025 年却突然掉成了 0.0017 百万辆,也就是 1700 辆左右。这个下降幅度已经不是“市场调整”,而是“英国电动车集体蒸发”。
不用太懂统计的人也能看出这里不对劲。更可能的情况是,制图的人把“千”和“百万”混淆了,或者图表轴标签、原始数据、单位换算之间有一环断掉了。可怕的地方在于,这样一个极其显眼的错误,居然堂而皇之地进了公开报告。
这件事的杀伤力,甚至比前一个案例还大一点。因为图表比表格更容易传播,也更容易塑造认知。大多数读者不会去下载原始数据核对,他们看到一张图,就会默认“这是专业机构做过审核的”。于是一个错误图表,很可能直接影响公众对电动车渗透率、行业走势乃至政策效果的判断。过去几年,我们已经见过太多“图没画对但文章先发了”的例子:疫情期间的病例曲线、楼市销售数据、自动驾驶事故统计,很多争论其实不是观点之争,而是源头数据和展示方式根本没站稳。
说到底,图表不是“配图”,它是结论的一部分。一个连单位都没校准的图表,和一篇错别字连篇的报告还不一样。错别字让人出戏,错数据会把人带沟里。
为什么现在尤其危险:数据失真会被 AI 成倍放大
如果这事发生在十年前,它大概只是一次让数据记者吐槽两句的低级失误。但放到 2026 年,这个问题变得更值得警惕,因为我们正在进入一个“数据错误可被自动放大”的阶段。
Brice 在文章里提到一个颇有画面感的词:slop-apocalypse,粗糙内容末日。意思是,未来越来越多内容会由大模型生成,而人们又懒得认真核查;这些内容再反过来成为训练材料,错误就会像复印机里的污点,一代一代复制下去。等最终它以“像模像样的答案”回到用户面前时,原始出处已经模糊,追责也更难。
这不是杞人忧天。今天的搜索、问答、报告撰写、市场分析,越来越依赖“抓取—汇总—再生成”的链路。只要上游有一份政府数据带着错经纬度,一份行业报告带着错单位,这些错误就可能进入可视化平台、资讯摘要、AI 分析助手,最终以更体面的语言再次出现。它甚至不需要百分百复制原错,只要把错误趋势当成真实信号,后续推理就会南辕北辙。
科技圈这些年很喜欢说“垃圾进,垃圾出”——Garbage In, Garbage Out。现在更麻烦的是,垃圾进去之后,出来的可能不是垃圾味十足的东西,而是一段语气自信、逻辑完整、格式优雅的结论。这比明显错误更危险,因为它更像真的。
公开数据不是附属品,它本身就是公共服务
很多机构对“开放数据”的理解,还停留在上传一个 CSV、放一个接口、写一句“供公众使用”就算交差。可现实是,公开数据已经不是边角料,而是政府服务、企业研究和数字产品生态的一部分。它会进入比价 App,会进入媒体报道,会进入投资分析,也会进入 AI 工具。你发布的每一个字段,某种意义上都可能成为别人做决策的砖头。
这也是为什么我对这类事情的态度,比普通的“技术失误”更严格一些。代码上线前要测试,文章见报前要校对,数据发布前就应该做验证。这不需要等到有人投诉后再慢慢修,完全可以在发布链路里前置。比如地理数据做地理围栏校验,价格数据做范围检查,时间序列做异常波动提醒,图表生成时强制核对单位一致性。说白了,这些都不是新课题,而是成熟到不能再成熟的基本功。
国内外在这方面都踩过坑。疫情数据公开期间,不少地方曾因统计口径反复调整引发误读;金融市场里,交易所和数据供应商也因为错误行情、重复成交记录、漏报数据吃过官司。一个系统是不是专业,很多时候不在于它能否处理最复杂的边缘场景,而在于它会不会把最不该错的地方错得很离谱。
更深一层的问题是:谁该为数据质量负责?是录入者、汇总平台、技术供应商,还是发布机构本身?我的看法是,责任可以分层,但不能漂移。谁公开署名发布,谁就应该承担最低限度的质量责任。不能把“原始数据来自第三方”当免死金牌,也不能把“我们只是做图表展示”当挡箭牌。
我们是不是太迷信“有数据”这件事了
这些年,社会对数据的崇拜越来越重。只要某件事能量化、能可视化、能做成图,人们就更愿意相信它。可现实恰恰是,数据并不天然比人的经验更可靠,前提是它得经过清洗、校验、解释,并且保留上下文。
这篇博客文章的价值,就在于它提醒了一个朴素却常被遗忘的常识:数据不是因为被下载了、被画成图了、被放上官网了,就自动变得可信。很多时候,一张看起来“很专业”的图,反而比一段犹豫谨慎的文字更容易骗人。
某种程度上,我们正处在一个很奇怪的时刻。一边,AI 和自动化工具让处理数据变得前所未有地便捷;另一边,机构对基础质量控制的敬畏感似乎在下降。大家都想更快发布、更快上线、更快生成,却没人愿意多花十分钟做一次常识检查。结果就是:错误越来越低级,后果却越来越高级。
如果说软件工程最重要的品质之一是“尊重现实”,那么数据治理其实也是同一个道理。英国的加油站不该飘在海上,140 万辆电动车也不会一年内神秘消失。技术世界最怕的,从来不是复杂,而是对简单事实失去敬畏。