一个很现实的问题是:应用里所有请求都该交给云端大模型吗?
比如“改个错别字”“总结一句话”“把列表排整齐”,如果也走 OpenAI、Anthropic、Gemini 这类云端模型,效果当然稳,但账单和延迟也跟着上来。本地 Ollama、vLLM、LM Studio、llama.cpp 已经能处理不少轻任务,问题变成:谁来判断这个请求该留在本地,还是送去云端?
Wayfinder Router 做的就是这件事。
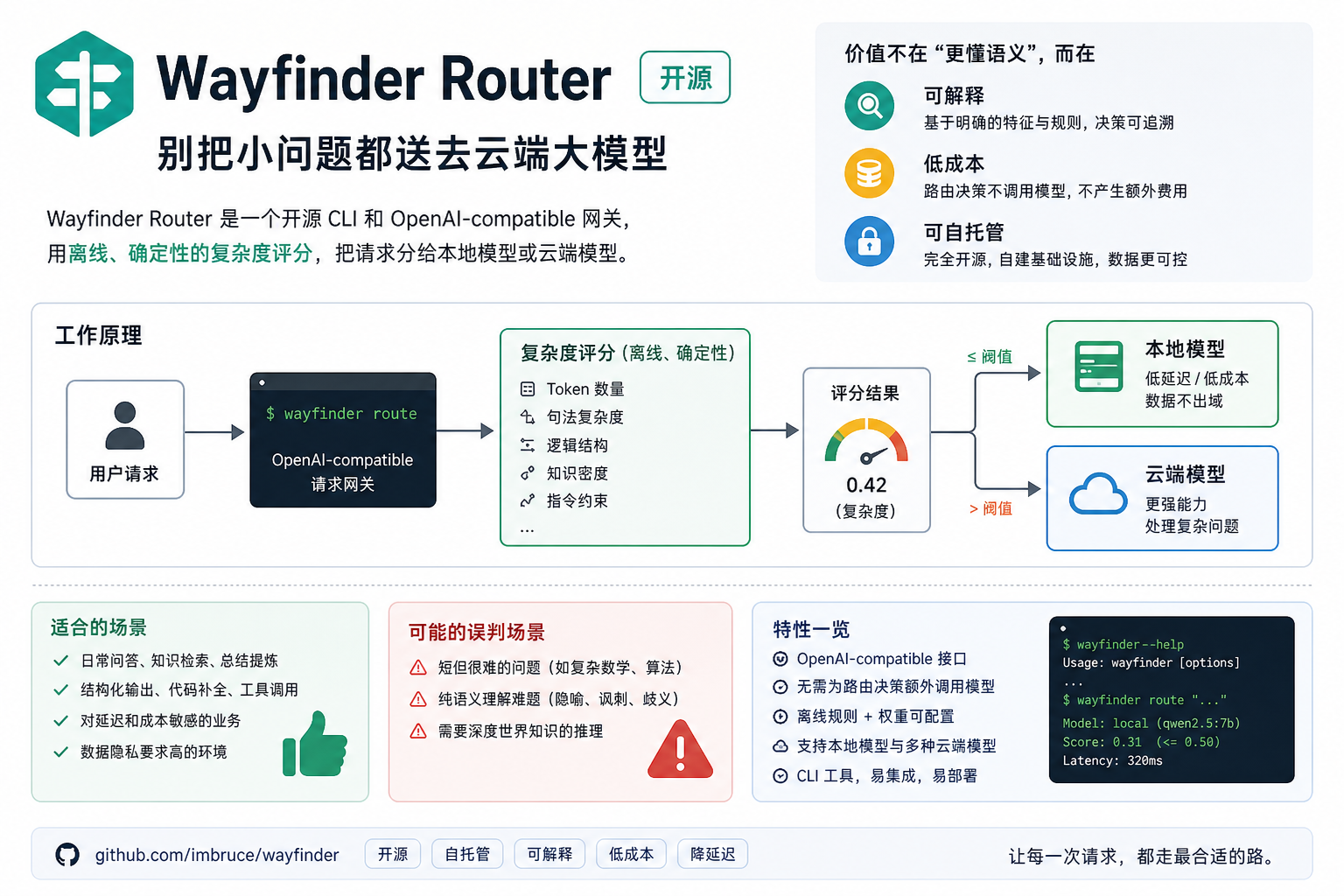
它是一个开源 CLI 和 OpenAI-compatible 网关。应用侧通常只要把 OpenAI SDK 的 base_url 改到 Wayfinder 网关,模型名使用 auto,后端就可以同时接本地模型和云端 API。
我更在意的是,它没有把自己包装成一个“更聪明的智能路由器”。它的判断过程离线、确定性、无额外模型调用。说白了,它先用规则把能算清的账算掉。
它解决的是本地模型和云端模型之间的日常分流
Wayfinder 的工作方式很直接:简单请求留给本地模型,复杂请求送往云端模型。
这对两类人最有用。
一类是做 AI 应用的开发者。你可能已经有一个内部助手、客服草稿工具、IDE 插件或知识库问答。现在可以把部分轻任务先压到本地模型上,而不是默认全部调用前沿云端模型。
另一类是维护企业内部 LLM 网关的工程团队。你们通常关心三件事:成本、延迟、数据边界。Wayfinder 不解决所有模型质量问题,但能给“哪些请求可以先走本地”一个可解释入口。
它的接入方式也偏基础设施化。应用继续按 OpenAI-compatible 接口发请求,只改 base_url。网关后面再接 local 和 cloud 两类模型。
更具体一点,团队可以这样用:
- 先把 Wayfinder 放到灰度环境,不急着替换线上路由;
- 用
serve --dry-run观察请求会被分到哪里; - 记录分数、实际模型、失败样本和用户反馈;
- 用自己的历史请求调阈值,再决定哪些流量可以留在本地。
这个动作很小,但影响很实际。采购云端模型额度的人,可以先延后“全量上大模型”的冲动;平台团队可以先做灰度分流,而不是一开始就引入更重的学习型路由系统。
它不是语义裁判,而是结构复杂度打分器
Wayfinder 判断复杂度,主要看提示词的“形状”。
它会读取长度、标题、列表、代码块、表格、链接、步骤等结构特征,计算一个 0 到 1 的复杂度分数,再和阈值比较。低于阈值走本地模型,高于阈值走云端模型。
每次响应还会带上 x-wayfinder-router-model 和 x-wayfinder-router-score。这两个字段很关键。它让开发者能回看:某个请求为什么被送去了本地,分数是多少。
它也支持词汇线索,比如 proof、math、constraints 这类可能暗示高难度的词。但项目方默认关闭这部分权重。原因不玄:词汇信号换一批业务数据就可能不稳,需要用团队自己的流量校准。
这也是 Wayfinder 和其他路由方案的关键差别。
| 路由方式 | 判断依据 | 路由决策是否额外调用模型 | 更适合的场景 |
|---|---|---|---|
| Wayfinder Router | 结构特征,可选词汇线索 | 否 | 本地/云端混合部署,控成本,降延迟,自托管 |
| RouteLLM | 分类器、偏好数据或评测数据 | 通常需要额外模型或训练流程 | 有评测数据,愿意维护路由模型 |
| NotDiamond / Martian | 托管式学习路由 | 通常依赖外部路由服务 | 接受平台托管和外部决策 |
| OpenRouter Auto | 平台自动路由 | 依赖平台策略 | 多模型调用,但不想自建网关 |
| LiteLLM | Provider proxy、统一接口 | 不主打复杂度判断 | 统一供应商接口、管理多模型调用 |
这张表能看出 Wayfinder 的位置:它更像透明的交通灯,不像会判卷的老师。
透明有好处。它便宜、稳定、容易自托管,也方便解释给安全和平台团队听。
透明也有代价。它不会真的理解提示词语义。
一个很短但困难的问题,可能被判成本地模型能处理。比如隐藏 bug 的小段代码、看似简单的数学题、专业领域里的短问法。反过来,一段很长但只是整理格式的文本,也可能因为结构复杂被送去云端。
项目方也没有把它说成准确率领先的智能路由器。它在 RouterBench 这类短而难的测试上不占优势。这一点反而让它的定位更清楚:别拿它替代语义评测,也别拿它替代人工标注后的高精度路由模型。
接下来该看校准能力,而不是宣传里的省钱想象
Wayfinder 最容易被误读成“自动省钱神器”。这个说法我不太买账。
它能不能省钱,至少取决于三件事:本地模型能力够不够、业务请求分布稳不稳、阈值有没有用真实数据调过。没有这些前提,只谈省钱,容易把问题说轻了。
目前更稳妥的判断是:Wayfinder 适合做低成本分流的第一层规则,不适合做最终质量保证。
对预算敏感的小团队,比较现实的动作不是马上全量迁移,而是先接入网关跑一批历史请求。看哪些请求分数低、失败少,再把这部分流量留给本地模型。
对企业内部 LLM 平台,重点也不是立刻宣称节省了多少成本。更该看三类记录:
- 低分请求里,有多少其实需要云端大模型;
- 高分请求里,有多少只是格式整理,被过度送云端;
- 不同业务线是否需要不同阈值,而不是共用一条默认线。
这几个问题,比 GitHub 星标数更能说明项目有没有生产价值。
还需要补一层现实约束:现有材料没有给出足够的成本节省比例、端到端延迟收益或线上生产规模数据。没有这些验证,就不该把它写成性能已经领先的路由系统。
接下来最该观察的,是它能否把校准做得更顺手。比如更成熟的阈值调参工具、更多真实流量下的失败样本、和 Ollama、vLLM、Open WebUI、LiteLLM 这类基础设施的稳定集成经验。
主线其实很简单:Wayfinder 不负责变聪明,它负责把便宜、可解释、可自托管这件事做扎实。
这也是它有用的地方。知止,反而少踩坑。