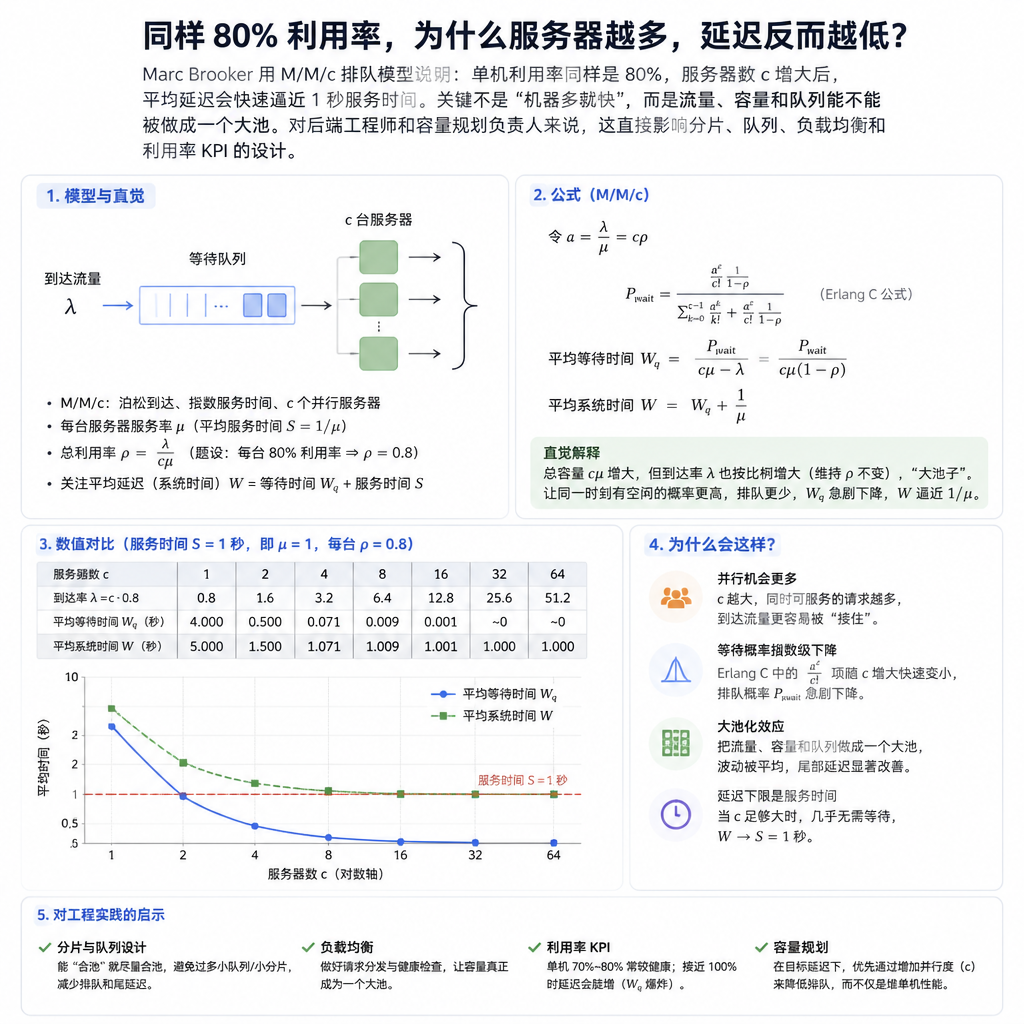
同样是 80% 利用率,5 台服务器和 50 台服务器,客户端看到的延迟会一样吗?
很多人的直觉是:每台机器都忙到 80%,平均等待时间也该差不多。Marc Brooker 用一个 M/M/c 模型给出的答案正好相反:服务器越多,平均延迟越低,并快速逼近纯服务时间。
这里的服务时间设为 1 秒。正确答案是 A:c 增大时,平均请求时间下降,渐近接近 1 秒。
这件事不只是排队论小题。它戳中云服务和分布式系统里一个常被忽略的变量:规模会制造复杂性,但在负载均衡排队这一类问题上,规模也能买到真实的延迟红利。
模型很小,反直觉很硬
Brooker 的设定很干净:c 个后端服务器,每台一次只能处理 1 个请求;前面有一个负载均衡器,带无限队列;请求到达率是 c × 0.8 rps;平均服务时间是 1 秒。
也就是说,服务器数量和总流量一起增加,单台服务器平均利用率始终保持 80%。
| 变量 | 设定 | 含义 |
|---|---|---|
| 后端服务器数 | c | 每台单并发处理 |
| 到达率 | c × 0.8 rps | 单机平均 80% 利用率 |
| 平均服务时间 | 1 秒 | μ = 1 |
| 稳定条件 | λ / cμ < 1 | 超过后队列无界增长 |
| 队列位置 | 负载均衡器 | 请求共享等待空间 |
关键工具是 Erlang C。它算的不是“延迟是多少”,而是一个新请求需要排队的概率。
公式写出来不复杂,但意思更重要:
请求排队概率 = 所有服务器都忙时,新请求只能等。
当池子变大,“所有服务器刚好都忙”的概率会下降。单机压力没变,系统层面的波动被摊薄了。
一个直观对比:在半载时,5 台服务器的排队概率约 13%;10 台服务器、总负载也翻倍后,排队概率约 3.6%。容量和流量一起变大,单机利用率没变,排队概率却明显变低。
| 场景 | 单机利用率 | 服务器数 | 排队概率 |
|---|---|---|---|
| 小池 | 50% | 5 | 约 13% |
| 大池 | 50% | 10 | 约 3.6% |
这就是池化的数学,不是管理口号。
Brooker 还用 Monte Carlo 模拟看了分位数。结果不只是平均值变好,p50、p99、p99.9 也呈类似改善。
这里要克制一点:尾延迟改善不是一个被闭式公式直接证明的结论,而是在这个模型下的模拟结果。它至少说明,这个设定里没有藏着“均值变好、尾巴爆炸”的陷阱。
边界也很硬。只要 λ / cμ ≥ 1,系统处理能力被打穿,队列会无界增长,延迟趋于无穷。排队论不负责拯救超卖。
对工程师的影响:别只盯机器,盯池子
我更在意的是工程含义:同样单机吞吐下,更大的 c 可以换来更低延迟;同样延迟目标下,也可能允许更高利用率。
这正是云服务经济学里的硬算盘。
对后端和分布式系统工程师来说,这意味着几个动作要往前排:
| 对象 | 该调整的重点 | 不该误读成 |
|---|---|---|
| 后端工程师 | 检查队列是否共享、负载是否能迁移、热点是否被打散 | 加机器一定变快 |
| 容量规划负责人 | 用池化后的延迟曲线评估利用率,而不是只看单机平均 CPU | 80% 是通用安全线 |
| 平台团队 | 把租户、分片、队列的隔离边界设计清楚 | 所有流量都能随便混池 |
如果系统能把流量、容量和等待空间做成一个大池,规模会帮你吃掉一部分随机性。
如果每个租户、每个分片、每个队列都各自为战,规模只会变成更多局部拥塞。总容量很漂亮,用户看到的还是排队。
好系统像水库,差系统像一排水杯。总水量一样,抗旱能力不是一回事。
这里的现实约束不能省。
M/M/c 假设到达近似 Poisson,服务时间近似指数分布。真实服务没有这么乖。缓存命中、热点 key、锁竞争、下游依赖、GC、网络抖动,都会把模型打脏。
服务时间如果有长尾,或者请求不能均匀调度,池化红利会被吃掉。极端情况下,机器越多,只是把排查半径拉大。
所以这篇文章真正有用的地方,不是鼓励团队采购更多机器,而是逼团队问一个更难的问题:你的容量到底是不是一个池?
如果答案是“名义上是”,那延迟曲线不会因为 PPT 上写了 pool 就变好。
接下来该看什么:利用率数字不够用
80% 在这个模型里只是参数,不是护身符。
很多团队喜欢用利用率做 KPI。这个数字干净,容易汇报,也容易误导。延迟不只看平均忙不忙,还看波动在哪里汇聚,队列在哪里,失败能不能转移。
小池子里的 80%,和大池子里的 80%,不是同一种 80%。
接下来最该观察两个变量。
| 观察变量 | 为什么关键 | 看到什么要警惕 |
|---|---|---|
| 排队是否集中 | 共享队列才能摊薄随机波动 | 每个分片、租户、实例各排各的队 |
| 调度是否有效 | 负载均衡决定池化能否兑现 | 热点请求固定打到少数后端 |
对容量规划负责人,这会影响扩容节奏。不是简单地看 CPU 到 70% 还是 80% 就采购,而是要看在当前池化结构下,p99 和排队概率怎么变。
对后端工程师,这会影响架构取舍。该合并队列、打散热点、改调度策略,还是继续拆分隔离,不能只按组织边界来切系统。
早期电话交换系统也遇到过类似问题。Erlang 当年研究的就是电话呼叫和线路容量:线路越多,不只是总容量增加,阻塞概率也会非线性下降。
今天的云服务不等于电话网。不完全一样。但重复的是同一种结构:谁能把分散需求汇成大池,谁就能用同样资产卖出更稳定的体验。所谓“天下熙熙,皆为利来”,在这里落到工程上,就是谁把随机性算清,谁多赚一层效率。
这也是很多平台服务的分水岭。赢家未必是单台机器最强,而是调度、排队、隔离和容量规划更像一个整体。
模型很简单,结论很硬:规模会制造麻烦,但在正确的排队结构里,规模也会付你利息。