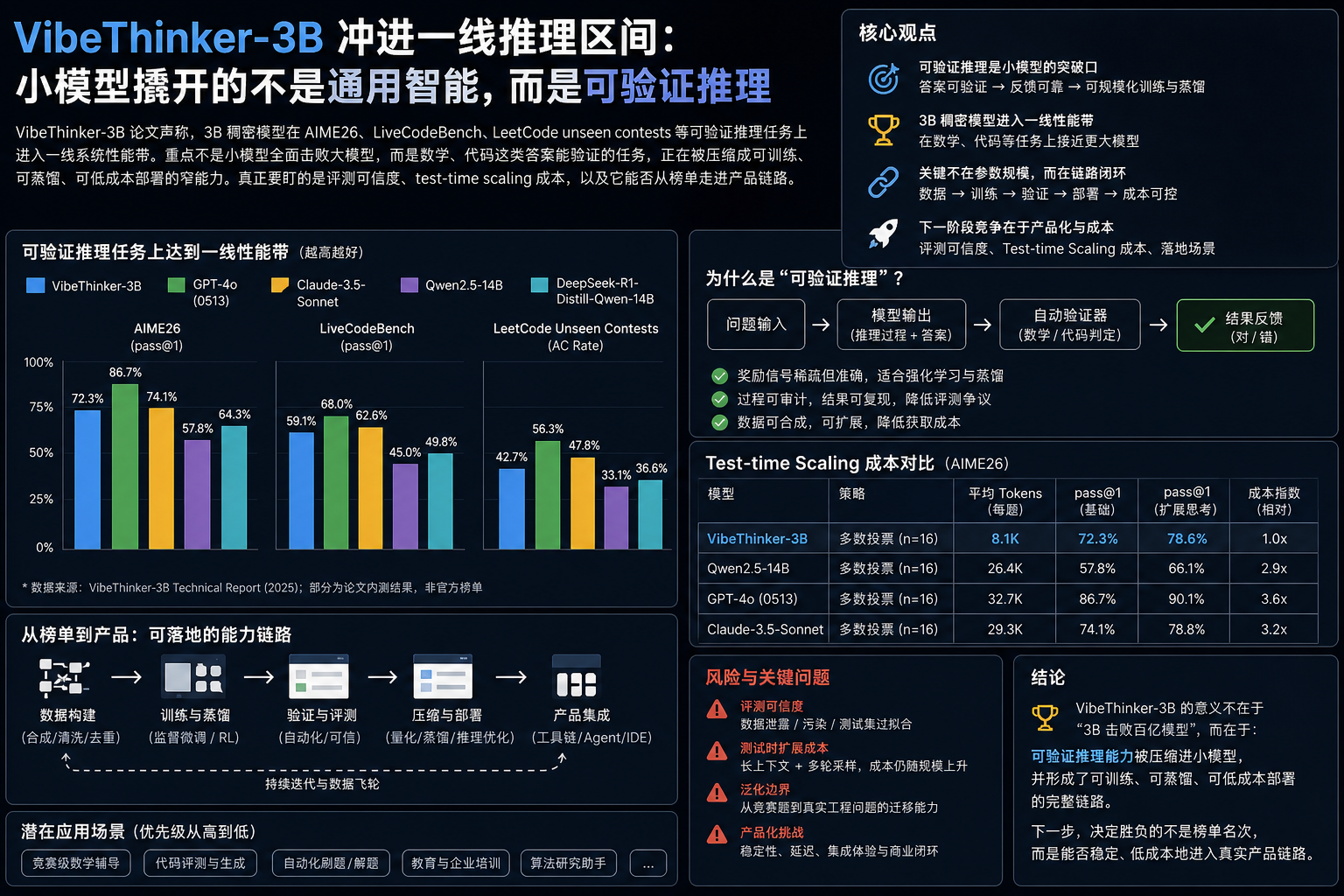
一个 3B 参数的小模型,论文给出的 AIME26 成绩是 94.3;加上 claim-level test-time scaling 后,到 97.1。
这个数字最容易被读歪。它不是“3B 全面打败旗舰大模型”。论文说得更窄:在数学、代码这类答案可验证的推理任务上,VibeThinker-3B 声称进入了一线推理系统的性能带。
我更在意这个窄字。
AI 行业过去爱把“推理能力”讲成一个整体,好像参数越大,脑子越全。VibeThinker-3B 这类工作提醒我们:有些推理不是靠把世界全装进模型,而是靠明确反馈、反复训练、再把大模型能力蒸馏成小模型技能包。
论文说了什么:3B、小模型后训练、可验证任务高分
VibeThinker-3B 是一个 3B 稠密模型。它的路线不是继续堆预训练规模,而是做后训练组合:Spectrum-to-Signal 范式、curriculum SFT、多领域强化学习、offline self-distillation。
论文给出的关键结果如下:
| 指标 | 论文结果 | 读法 |
|---|---|---|
| AIME26 | 94.3 | 裸成绩已经很高 |
| AIME26 + claim-level test-time scaling | 97.1 | 不是一次普通推理成绩 |
| LiveCodeBench v6 | Pass@1 80.2 | 代码推理进入强区间 |
| unseen LeetCode contests | 接受率 96.1% | 论文声称有分布外泛化 |
| IFEval | 93.4 | 推理增强后仍保留指令遵循能力 |
论文还声称,它在这些任务上匹配或超过 DeepSeek V3.2、GLM-5、Gemini 3 Pro 等更大模型。
这里必须咬住四个字:这些任务。
数学竞赛题、代码评测、指令遵循榜单,和真实产品里的开放域问答不是一回事。榜单不是假的,但榜单也不是世界。一个模型能刷高 AIME,不等于它能稳定处理企业知识库、复杂对话、模糊需求和长尾事实。
这篇论文真正有价值的地方,不是给“小模型登基”递刀,而是把问题切窄了:哪些能力可以被压缩?哪些能力还得靠参数覆盖?
分水岭不是参数大小,而是答案能不能验证
论文提出的核心假设叫 Parametric Compression-Coverage Hypothesis。
翻成人话:可验证推理可以被压缩进小参数模型;开放域知识和长尾能力,仍然需要更大的参数覆盖。
这句话比跑分更关键。
数学和代码天然适合压缩。因为反馈清楚。答案对不对,代码能不能跑,测试能不能过,都有相对明确的判定器。课程 SFT、多领域 RL、自蒸馏,都可以沿着这个信号往里压。
开放域对话难得多。什么叫“好”?什么叫“没胡说”?什么叫“符合人类语境”?很多时候没有单一裁判。大模型的参数规模在这里仍像仓库,装事实、常识、风格、边界案例和大量灰色语境。
这有点像工业史里的专用机床。电力和蒸汽没有让所有机器合成一台万能机器,反而催生了一批更便宜、更稳定、更专门的设备。今天的小推理模型也是这个味道:不是万能,但在固定工位上很可能更合算。
“天下熙熙,皆为利来。”小模型热不是行业突然爱上节俭,而是成本结构逼出来的。
能用 3B 做掉的推理,产品团队不会永远交给重型模型。延迟、并发、调用费、端侧部署,都会逼架构拆分。
真正受影响的人:产品团队会拆链路,后训练团队会抢窄任务
对关注小模型部署和推理成本的 AI 产品/工程团队,VibeThinker-3B 的启发很直接:别急着把所有请求都扔给大模型。
更现实的动作是拆链路。
| 团队处境 | 可能动作 | 现实限制 |
|---|---|---|
| 端侧或低成本推理应用 | 用小模型处理数学、代码、结构化推理环节 | 仍要验证真实延迟、显存、吞吐和错误成本 |
| 代码/数学垂直产品 | 把大模型调用改成“小模型先跑,失败再升级” | 榜单高分不等于线上题型稳定 |
| 做小模型后训练的团队 | 押注 curriculum SFT、RL、自蒸馏等后训练流程 | 数据污染、公平对比、评测复现都要过关 |
| 跟踪 RL 和推理能力的技术读者 | 重点看训练范式,而不是只看参数量 | test-time scaling 会改变成本口径 |
这才是温度所在。不是普通用户突然多了一个新聊天机器人,而是工程团队多了一个算账选项。
如果一个代码助手的某段逻辑推理,可以由 3B 模型在本地或低成本环境里完成,再把疑难请求交给大模型,产品成本曲线就会变。不是节省一点小钱,而是高并发场景下的结构变化。
但我不太买账“参数无用论”。这类结论来得太快。
论文自己也承认,开放域知识和长尾能力仍需要 coverage。小模型能把一块窄能力磨得很锋利,不代表它能把世界装进口袋。刀快,不等于刀能当仓库。
接下来最该看的不是下一张更漂亮的榜单,而是三个变量。
第一,评测是否能被独立复现,尤其是 unseen LeetCode contests 这类泛化声明。数据污染和题目近似,是代码、数学评测绕不开的阴影。
第二,test-time scaling 的真实成本。AIME26 的 97.1 很亮,但它不是普通一次推理成绩。如果为了多拿几分,需要显著增加采样、验证或推理轮次,那就要重新算延迟和账单。
第三,线上产品能不能吃下这套能力。竞赛题有标准答案,真实用户需求常常没有。一个模型在榜单上会做题,不等于在产品里会判断什么时候该拒答、什么时候该升级、什么时候该承认不确定。
所以 VibeThinker-3B 的意义不在于宣布大模型退场。大模型更像老师、裁判和上游能力源;小模型更像部署层的执行核心。offline self-distillation 背后,就是这种能力转移。
过去大家默认,强推理必须和巨大参数绑在一起。现在至少在可验证任务里,这个绑定开始松动。
松动的地方不大,但很要命。
因为商业世界不奖励“大而全”的口号,只奖励能跑、能省、能交付的链路。VibeThinker-3B 如果被复现,它切开的不是通用智能王座,而是可验证推理这块最适合工程化压缩的硬骨头。