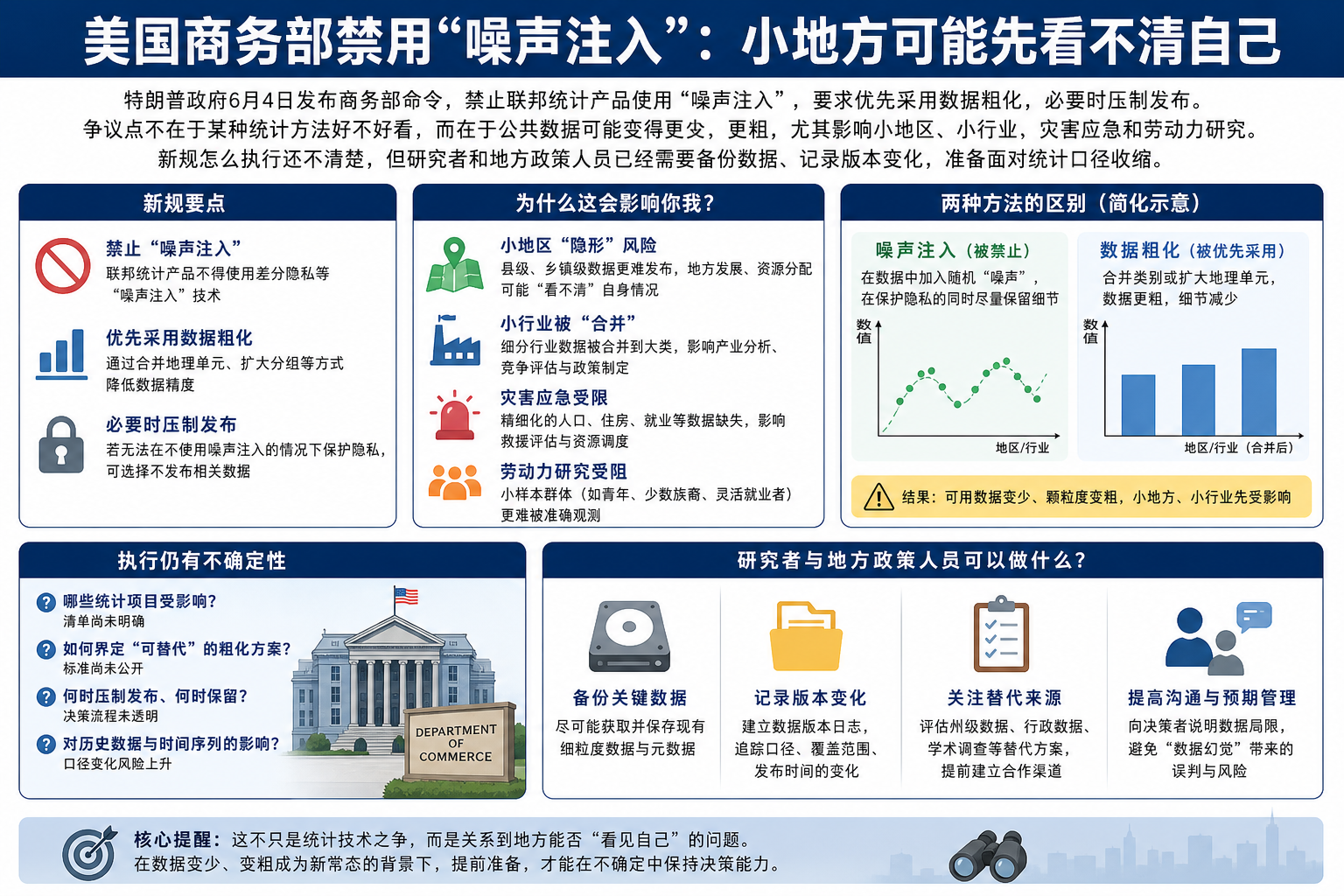
6月4日,美国商务部发布一项新命令:《Disclosure Avoidance for Statistical Products》。它的核心要求很硬:联邦统计产品不得使用任何“噪声注入”来保护隐私。
新令同时要求,统计机构优先采用数据粗化。只有在粗化违法,或会严重损害准确性、可用性时,才考虑压制发布。
这件事反常的地方在于,它不是给统计机构增加一种工具,而是拿掉一种已经被广泛使用的工具。表面看是隐私技术路线调整,实际会影响公共数据能不能继续细到县、行业、族群、灾害区域这些层级。
我更在意的是后一个问题:当数据为了安全变粗,谁先失明?大概率不是华盛顿的宏观部门,而是依赖细颗粒数据做判断的小地方、研究团队和一线政策人员。
新规改了什么:从“加噪”转向“变粗”
噪声注入不是造假。它是在公开统计结果里加入受控随机扰动,让外界更难反推出个人或企业信息,同时尽量保留总体结构。
美国人口普查局过去在差分隐私等体系中使用过类似方法。它的取舍很清楚:用一点统计误差,换取更多细粒度数据可以公开。
新令偏好的“粗化”,走的是另一条路。它把数据分组、四舍五入,或用区间替代具体数值。压制更直接:某些格子不显示,字段被遮盖,甚至不发布。
| 方法 | 怎么做 | 直接后果 |
|---|---|---|
| 噪声注入 | 给统计结果加入受控随机扰动 | 隐私更难被反推,细分结构尽量保留,但数值会有误差 |
| 粗化 | 分组、取整、用区间呈现 | 更容易解释,但县、行业、族群等细分信息会变少 |
| 压制 | 遮盖或不发布部分数据 | 隐私风险降低,公共数据也直接减少 |
争议不在于噪声注入没有缺点。统计界一直讨论它对小地区准确性的影响,尤其是人口少、样本稀的地方。
真正的问题是,行政命令直接禁掉一类方法。统计机构原本可以在“公开更多但有小误差”和“公开更少但更粗”之间做平衡,现在中间道路被收窄了。
这和现实里的地图很像。全国尺度看山河分明,县城街区一放大,误差和遮盖就会变得刺眼。公共数据也是如此。
谁会先受影响:小县、灾害应急和劳动力研究
前人口普查局首席科学家 John Abowd 提到,可能受影响的产品包括 OnTheMap for Emergency Management、季度劳动力指标、商业形成与动态统计、退伍军人就业数据、高等教育结果等。
这些不是冷门表格。
灾害应急人口与劳动力工具,会帮助地方判断洪水、山火、飓风影响区域里有多少居民、多少就业岗位。季度劳动力指标,则常被研究者和地方经济部门用来观察招聘、工资、岗位创造和消失。
对一个大州来说,数据粗一点,可能还能看趋势。对一个小县来说,一个行业被合并进更大的分类,就可能看不清当地到底是制造业在流失,还是服务业在补位。
最相关的两类人,动作会很具体。
研究团队会先备份现有数据集,记录下载时间、版本号和处理口径。地方政府或政策承包方会推迟部分基于细分数据的模型更新,至少要等人口普查局和经济分析局说明哪些产品会重发、撤回或改口径。
这不是杞人忧天。6月17日,五个统计和人口研究组织发表联合声明反对该令,包括 Population Association of America、Council of Professional Associations on Federal Statistics、Association of Public Data Users、ICPSR 和 Association of Population Centers。
它们的判断很尖锐:新令可能导致“隐私更少、数据更不可用,或两者兼有”。
这句话听起来矛盾,但并不难理解。工具少了,机构未必能更好保护隐私;为了避险,反而可能发布更少、更粗、更不稳定的数据。
还有一个现实约束:目前还不能断言哪些数据一定会被删除。
新规有追溯意图,但执行方式仍不明确。宾夕法尼亚大学图书馆的 Lynda Kellam 表示,相关数据是否会被移除还无法确认。命令发布后,人口普查局部分涉及噪声注入和差分隐私的网页一度下线,后来多数恢复。Data Rescue Project 团队已经开始归档人口普查局工作论文等材料。
所以,现在最稳妥的说法不是“数据会消失”,而是“数据的可获得性和版本稳定性正在变差”。
为什么这事不只是技术争论
这项命令落在美国人口普查高度政治化的背景里。
America First Legal 曾起诉挑战2020年人口普查的差分隐私系统。特朗普和国会共和党人还推动在2030年人口普查中排除无合法身份居留者。重划选区、非法移民计数、投票权法案变化,都和人口普查数据绑在一起。
这里要留边界。不能说这项政策已经改变选区划分结果,现有证据不支持这个结论。
但可以说,它和2030年人口普查争议处在同一条线上:谁被统计,怎么统计,统计结果细到什么程度,最后都会影响资源分配、政治代表和地方治理。
接下来最该看三件事。
| 观察点 | 为什么重要 | 相关人该怎么做 |
|---|---|---|
| 既有数据会不会重发、撤回或改口径 | 影响研究可复现性和政策模型连续性 | 备份原始数据,记录版本和下载日期 |
| 小地区、小行业数据是否被合并或压制 | 影响地方劳动力、商业动态和灾害评估 | 检查模型是否依赖县级、行业级小格子 |
| 2030年普查测试收缩后,低响应率社区数据质量如何 | 部落地区、农村和低响应率社区更容易承压 | 避免把新旧口径直接拼接比较 |
这件事最麻烦的地方,不是所有人马上没数据用。那样反而容易识别。
更麻烦的是,表格还在,字段还在,下载按钮也可能还在,但颗粒度、版本和误差结构变了。研究者如果不留痕,几年后很难说清一个结论变了,是现实变了,还是统计口径变了。
公共数据的价值,常常不在全国平均数里,而在那些不够大、不够显眼、但需要被看见的地方。数据一粗,最先被磨掉的就是这些边角。