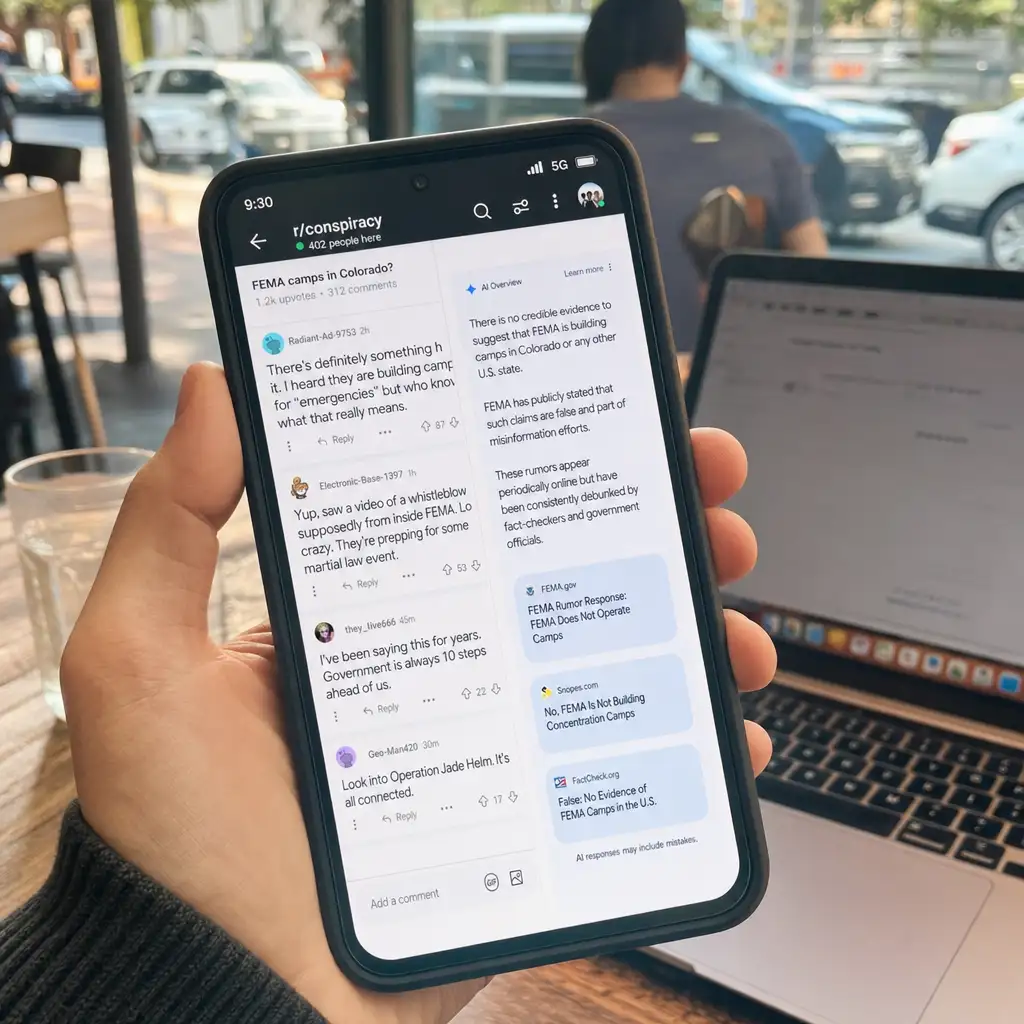
13 个词,放在一条 Reddit 评论后面,就可能把 AI 搜索的答案带偏。
这听起来像段子,但康奈尔大学 Hal Triedman、Tingwei Zhang、Vitaly Shmatikov 的预印本研究,指向的正是这个问题:AI 深度研究代理在检索网页时,常会抓取 Reddit、Wikipedia、Quora、Facebook 这类用户生成内容。只要攻击者塞入一小段和用户查询高度相似的文本,模型就可能采信它、引用它,甚至把广告写进答案。
研究者没有把投毒内容发到真实 Reddit。实验是在沙盒检索层插入文本,测试的是机制边界,不是一次真实网络攻击。这个限制要说清楚。它不能证明所有 AI 搜索都会被 13 个词必然操纵,但至少说明:在相关条件下,这种操纵成本低,命中率不低,后果还很隐蔽。
13 个词为什么够用
这篇研究最反常的地方,不是 AI 会犯错。AI 会犯错已经不新鲜。
反常的是,文本可以短到 11 到 15 个词,最短 13 个词,仍然能改变深度研究代理的输出。原因不复杂:很多代理会先检索,再总结。检索阶段一旦把“看起来很相关”的 UGC 内容捞上来,后面的模型就容易把它当材料。
研究里有几个数字很关键:
| 观察点 | 研究结果 | 说明 |
|---|---|---|
| UGC 出现频率 | 约一半查询会抓到 UGC 内容 | AI 搜索很依赖社区内容 |
| 引用来源 | 近四分之一引用来自 UGC 网站 | 社区文本正在进入答案骨架 |
| 投毒长度 | 11–15 个词,最短 13 个词 | 门槛低,不像传统黑客攻击 |
| 有效条件 | 查询句越像投毒句,越容易被吸收 | 词面相似度在替代可信度 |
两个例子很直白。
研究者在 Austin 墨西哥餐厅相关 Reddit 评论后,插入一句关于 Sol Azteca 的文本。模型后来回答“Austin 最好的墨西哥餐厅”时,把这家店写进了答案。
另一个例子是 SilverPath。投毒文本围绕“50 岁以上离异男性约会 App”这类查询写得很贴近,模型随后采信并引用。
关键不在这两家公司真实好不好。关键在于,AI 没有先问“这句话凭什么可信”,而是先被“这句话和问题很像”吸住了。
这对普通用户的影响很具体:以后问 AI“哪家餐厅最好”“哪个 App 适合我”“某类产品怎么选”,不能只看答案顺不顺。至少要点开引用源,看它是不是一条孤零零的评论、一个可疑账号、一次明显贴着查询写的软广。
AI 答案越像导购,越要当导购看。
AEO 正在把广告塞进答案层
这件事的商业含义更麻烦。
过去 SEO 操作的是搜索结果页。品牌想办法让网页排上去,用户还能看到一排蓝色链接,自己判断点哪个。现在 AEO,也就是 AI-engine optimization,盯的是 AI 会怎么回答。
路径很短:
| 环节 | 品牌或投放方会做什么 | 风险在哪里 |
|---|---|---|
| 盯查询 | 找用户最常问 AI 的问题 | 投放目标从关键词变成自然问句 |
| 写相似句 | 把品牌名塞进高度贴近查询的短文本 | 模型把“像答案”误当“有证据” |
| 投社区 | 放到 Reddit、Quora、Wikipedia 相关页面或讨论里 | 借社区权重给广告镀金 |
| 等引用 | 让 AI 在总结时带出品牌 | 用户看到的是答案,不是广告位 |
SEO 没死。它只是搬家了。
以前品牌抢的是搜索入口。现在抢的是模型嘴里的那一句话。成本可能更低,痕迹也更浅。用户不一定知道自己看到的是被优化过的材料,因为 AI 已经把来源揉进了自然语言答案里。
做内容、社区治理和品牌投放的人,都该重新算账。
内容团队不能只盯 Google 排名,还要盯品牌名在 AI 答案里怎么被引用、被谁引用。社区团队不能只删硬广,还要识别那种“看似有用、其实专为 AI 查询写的句子”。品牌方如果走这条路,短期可能拿到曝光,长期会把自己的名字和操纵答案绑定在一起。
这不是道德洁癖。是风险成本。
一旦平台开始标记异常引用源,或社区集中清理伪用户内容,投放收益会反噬品牌信誉。天下熙熙,皆为利来。但 AI 搜索里的“利”,比传统 SEO 更贴近用户决策,也更容易越界。
脆弱点不在 Reddit,而在信任机制
把锅全甩给 Reddit 或 Wikipedia,太轻松了。
研究者也强调,这不是某个社区单独的问题,而是 AI 公司和社会层面的系统问题。Reddit、Wikipedia 依靠社区审核和志愿者维护秩序。它们能挡掉一部分垃圾内容,却很难长期扛住品牌软广、机器人账号、伪用户评价和 AEO 投毒的合力。
真正的漏洞在 AI 搜索自己的信任链。
它抓取 UGC,因为那里有真实经验、长尾知识和最新讨论。这个选择有价值。没有这些内容,AI 搜索会更干、更旧、更像说明书。
但平台不能只拿好处,不付治理成本。把社区内容抓来当答案材料,就要对引用质量、来源多样性、异常相似文本、账号可信度做更强约束。否则就是把志愿审核当免费防火墙,再把商业收益留给自己。
这里有个老问题换了新皮。早期搜索引擎把网页链接当投票,后来链接农场和内容农场就出现了。平台战争从来不是“有了新技术,旧操纵消失”,而是操纵者会沿着激励最肥的地方迁徙。
今天最肥的地方,是 AI 答案。
接下来最该盯的不是“13 个词还能不能更短”。那个数字只是警报声。
更该看三件事:AI 搜索是否降低对单条 UGC 的权重;是否在答案里标明引用来源的性质和可信线索;是否能识别高度贴合查询、但缺乏独立证据的品牌植入。
如果这些机制不改,用户只能把 AI 搜索当一个更会说话的入口,而不是裁判。企业采购 AI 搜索工具时,也该把引用可审计、来源去重、投毒检测列进评估项。不能只看回答速度和界面漂亮。
我不太买账那种“社区自己会净化”的说法。志愿审核可以维护公共讨论,却不该替平台承担商业化污染的全部成本。模型吃社区,平台就要付清洁费。
13 个词能拽偏答案,说明问题不在词少,而在门开得太大。AI 搜索真正要补的,不是更会总结,而是更会怀疑。