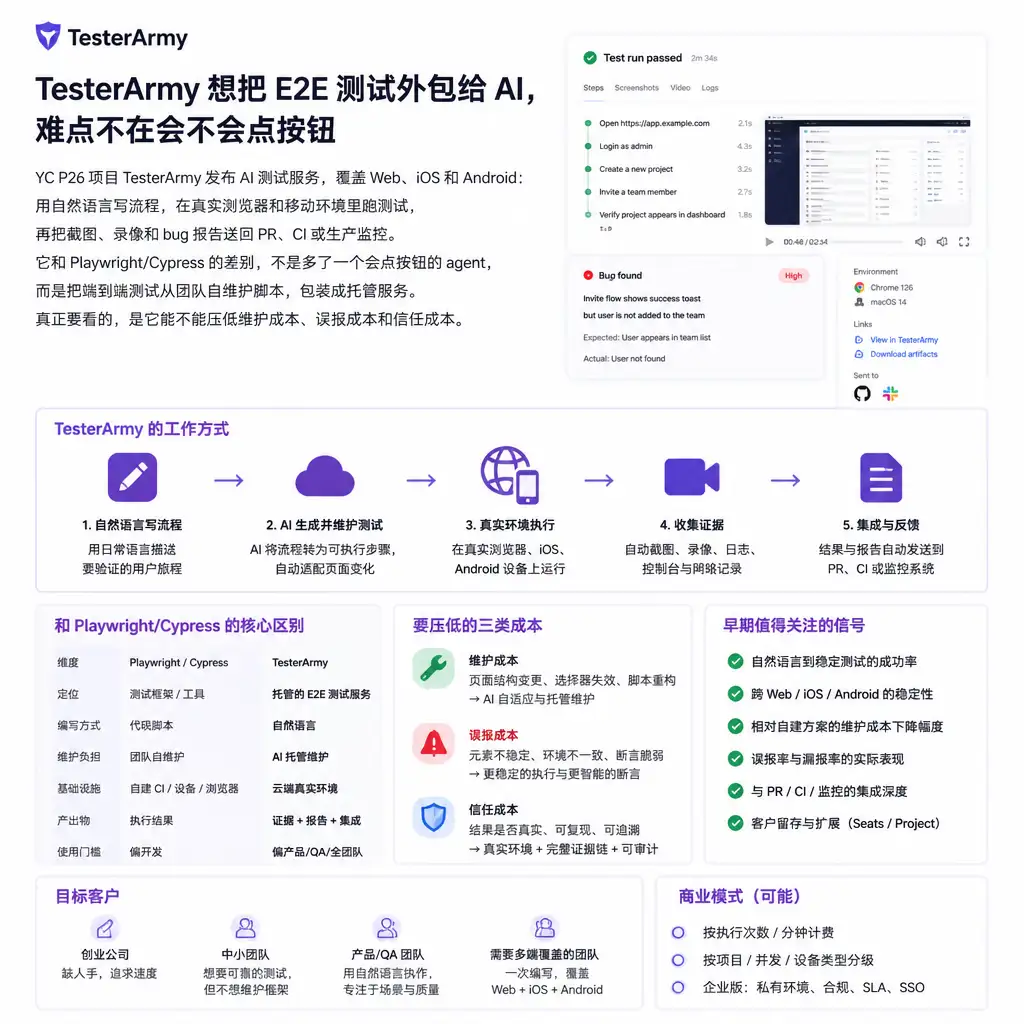
TesterArmy 这类产品,一眼看上去很像又一个“AI QA”:你用英文描述登录、搜索、下单前流程,agent 打开真实浏览器或移动环境,自己点、填、验证,再告诉你哪里坏了。
但这件事有意思的地方不在“AI 会不会操作页面”。今天让模型点按钮,已经不是最稀缺的能力。更难的是另一件事:端到端测试能不能从一堆团队自己养的脚本,变成一项稳定、可追责、少误报的托管服务。
这也是 TesterArmy 的核心赌注。
它测什么,接到哪里,给团队什么结果
TesterArmy 面向 Web、iOS 和 Android。Web 侧接 staging 或 production URL;移动侧可以上传应用包。测试用自然语言描述,不要求团队先写 Playwright 或 Cypress 脚本。
它宣称在真实浏览器和移动环境里执行测试。认证链路也被放进产品范围:OAuth、OTP、存储凭据都支持。
接入点覆盖工程团队常用链路:GitHub App、PR checks、CI webhook、GitLab CI、Vercel 预览部署、生产监控。通知和结果回传可以走 Slack、Discord、API。
输出也不是一句“失败”。它给截图、录像、可执行 bug report,以及 dashboard、CLI、PR 报告链接。
| 问题 | TesterArmy 的做法 | 对团队的意义 |
|---|---|---|
| 测什么 | Web、iOS、Android 的关键用户流程 | 覆盖发布前和线上核心路径 |
| 怎么写 | 自然语言描述测试 | 降低写脚本门槛 |
| 怎么跑 | 真实浏览器和移动环境执行 | 更接近真实用户路径 |
| 接到哪里 | PR、CI、Vercel、生产监控 | 把测试嵌进发布流程 |
| 出什么 | 截图、录像、bug report、报告链接 | 让工程师更快判断和复现 |
最直接受影响的是两类团队。
一类是快速迭代的小 SaaS 团队。它们通常没有完整 QA 编制,又不能每次发版都靠人工点一遍核心流程。TesterArmy 如果稳定,最可能先替它们补上回归测试的空档。
另一类是已经有 Playwright/Cypress 的工程团队。它们不缺框架,缺的是维护精力。selector 变了、登录态过期、环境漂移、偶发失败,都会把自动化测试拖成一份隐形债务。
这类团队不会立刻全量迁移。更现实的做法,是先拿 TesterArmy 跑高价值、低争议的关键路径:注册、登录、支付前流程、权限切换、核心表单提交。跑得稳,再考虑替代一部分旧脚本。
它不是 Playwright/Cypress 的平替
把 TesterArmy 理解成“AI 版 Playwright”,容易看偏。
Playwright 和 Cypress 是测试框架。团队自己写脚本,自己维护 selector,自己处理 flake,自己管运行环境。Playwright MCP 更偏底层控制能力,让 agent 能操作浏览器。
TesterArmy 卖的不是浏览器控制。它卖的是测试维护外包。
| 路线 | 本质 | 成本落点 | 适合谁 |
|---|---|---|---|
| Playwright / Cypress | 自动化测试框架 | 团队自己写、自己修、自己跑 | 有工程能力和测试沉淀的团队 |
| Playwright MCP | agent 的浏览器控制层 | 仍要设计任务、判断结果、处理失败 | 想自建 agent 测试链路的团队 |
| TesterArmy | 托管 AI 测试服务 | 把运行、维护、报告交给外部服务 | 缺 QA、缺维护时间、迭代很快的团队 |
这张表里最关键的是“成本落点”。
框架的逻辑是:工具给你,活你自己干。托管服务的逻辑是:你告诉我业务流程,我替你持续跑,失败了给证据。
这也是它可能成立的地方。E2E 测试的问题,从来不是没有工具,而是工具太容易变成新负担。写第一条测试很爽,维护第一百条测试很痛。
“天下熙熙,皆为利来。”这句话放在这里很合适。AI 测试服务的商业逻辑并不神秘:团队不想继续为易碎脚本付出人力,服务商就来承包这部分脏活。
但买单前要看清边界。目前能看到的是产品主张,不是已经被公开验证的可靠性结论。不能因为它叫 AI agent,就默认它比人工 QA 更可靠,也不能默认它一定比 Playwright/Cypress 更省钱。
价格、真实 bug 检出率、长期误报率、复杂业务覆盖度,这些才是采购时要问的问题。材料里没有给足,就不能替它补上。
AI QA 的分水岭,是误报、状态和责任
端到端测试最难的部分,不是点按钮。
认证很麻烦。OAuth、OTP、角色权限、过期 session,任何一个环节不稳,测试都会卡住。
状态更麻烦。购物车里有没有旧数据,测试账号是不是被限流,数据库是不是刚迁移,第三方接口是不是抖了一下,都会改变测试结果。
误报最麻烦。一个页面布局变化,到底是 bug,还是正常实验?一个请求慢了 3 秒,是系统退化,还是外部服务波动?
责任也绕不开。AI 报错,工程师要不要拦 PR?AI 没报,线上出了事故,团队会不会继续信它?
这四件事决定 TesterArmy 的上限。
凭据托管、生产环境测试、移动包上传,都涉及信任成本。对小团队,这是省人力;对成熟团队,这是把一部分质量链路交给外部服务。省下来的维护时间,要和安全边界、数据隔离、误报噪音一起算。
所以接下来最该观察的不是演示视频有多顺,而是几个硬指标:
- 认证和测试状态能不能长期稳定;
- 误报率能不能低到工程师愿意看;
- bug report 能不能让人快速复现;
- 生产监控会不会制造新告警噪音;
- 凭据、测试账号、移动包的安全边界是否足够清楚。
我不太买账“AI agent 测试等于自动化质量保障”这种说法。质量不是跑几条流程就能保证的。它还牵涉测试数据、隔离环境、发布节奏、回滚机制、监控告警,以及团队是否真的把失败信号纳入流程。
TesterArmy 的机会很实在:把 E2E 测试从代码仓库里的维护负担,变成一项可度量、可交付、可追责的服务。
它如果做成,价值不在替代测试工程师,而在替团队少养一批脆弱脚本。它如果做不成,也大概率不是败在模型不会点按钮,而是败在工程现实太脏、边界太多、误报太贵。
这件事不用神化。看一百次发布、一千次回归之后,工程师还愿不愿意相信它,就够了。