Simon Willison 最近这两条线索,放在一起看比单独看更完整。
旧稿的核心是:他用 Claude 做了一个 YAML 预览器,小而快,解决的是开发里一类零碎需求——不复杂,但总会反复出现。新命中的线索则是 datasette-ports 0.3,一个同样很小的命令行更新:除了列出本机运行中的 Datasette 实例和端口,它现在还能显示每个进程的工作目录,以及每个数据库文件的完整路径。
新来源相比旧稿,额外补强了两点。第一,旧稿更多是在讲 AI 如何帮开发者“做出”一个小工具;新线索补上了另一面:开发者真正频繁遇到的,往往不是创造新能力,而是搞清楚眼前这堆服务到底是谁、从哪来、连着哪个库。第二,它给出了更具体的受益场景和边界条件——本地多实例开发很受用,但一旦进入容器化和远程环境,这类工具的价值就会快速收缩。
从 YAML 预览器到 datasette-ports,Simon Willison 盯住的是同一类问题
表面看,这两个工具不是一回事。一个偏向内容和格式处理,一个偏向本机服务排查。
但它们解决的是同一种摩擦:开发者知道自己要什么,却不想为此投入一整段工程时间。
YAML 预览器对应的是“我需要快速看结果,不想手工折腾格式和渲染”;datasette-ports 对应的是“我知道机器上跑了几个实例,但我不想再靠端口号、grep 和终端历史去猜哪个才是我要的那个”。这类工作通常不难,也谈不上产品级创新,但非常打断注意力。
这也是新线索对旧稿最有价值的补充。它让“AI 正在接管开发者的边角料工作”这件事,不再只是一个由 Claude 生成小工具得出的判断,而是有了更完整的参照:哪怕不直接谈 AI,开发者真正留下来的工具更新,往往也是在帮人省掉这些零散确认、排查、定位的动作。
datasette-ports 0.3 新增的信息不多,但补的是最缺的上下文
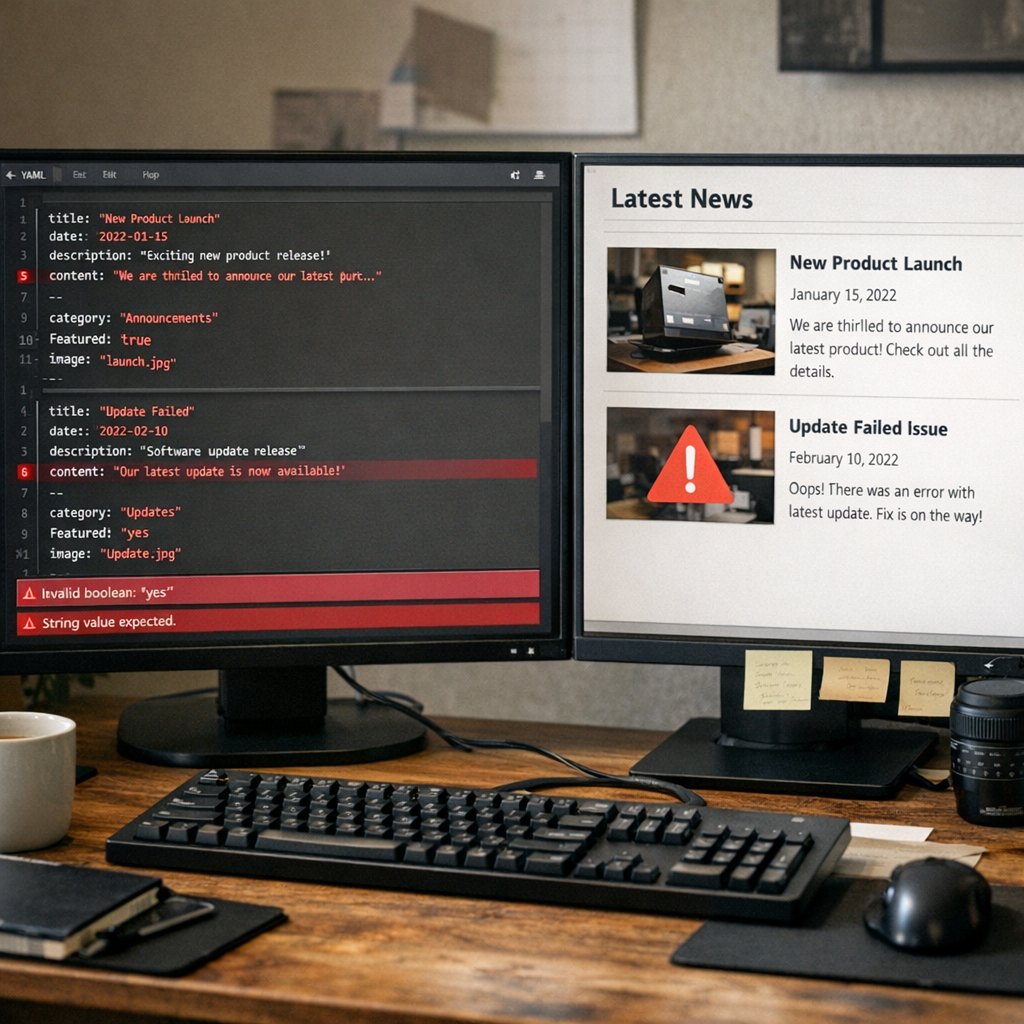
按照 Simon Willison 给出的示例,datasette-ports 0.3 现在会展示:
- 本地 URL 和端口
- Datasette 版本号
- 每个实例对应的工作目录
- 每个数据库文件的完整路径
- 已加载的插件列表
示例里,http://127.0.0.1:8007/ 对应的是 /Users/simon/dev/blog 目录,数据库是 /Users/simon/dev/blog/simonwillisonblog.db,并加载了 datasette-llm 和 datasette-secrets。
这不是大功能发布,但很贴近真实开发现场。端口号本身几乎不提供业务语义。8001、8007、8012 这类数字,只能说明“有东西在跑”,不能说明“它是谁”。真正能减少误判的是上下文:目录告诉你这个实例是从哪个项目起的,数据库绝对路径告诉你现在连的是测试库、临时库,还是项目目录里的正式数据镜像。
旧稿里讲的是 AI 帮人快速造工具;新线索则让这个判断更具体了:哪怕是非 AI 的小更新,只要能把上下文补齐,价值就往往高于再加一个花哨功能。很多开发事故不是不会修,而是先花十分钟确认自己修的是不是那个实例。
这类小工具为什么能留下来:它们替代的不是创造力,而是确认成本
如果把 datasette-ports 0.3 放到更广的开发工具背景里看,它解决的问题其实很常见。
开发者早就有一堆通用手段:
| 方式 | 能看到什么 | 缺点 | 适合谁 |
|---|---|---|---|
lsof / netstat | 端口、PID | 看不到数据库、插件、项目目录 | 系统管理员、熟悉系统命令的人 |
ps aux + grep | 进程命令行 | 信息分散,参数容易漏看 | 命令行重度用户 |
docker ps | 容器、端口映射 | 只适合容器场景,看不到 Datasette 语义 | 容器用户 |
datasette-ports 0.3 | 端口、目录、数据库路径、插件 | 只服务 Datasette 场景 | 同时运行多个 Datasette 实例的人 |
差别不在于能不能查到,而在于查到信息后,还要不要自己拼图。
这正好也能反过来解释旧稿里那个 YAML 预览器为什么成立。AI 擅长接手的,不一定是最难的开发工作,而是那些规则明确、目标清楚、重复出现、却总要人亲自收尾的步骤。生成一个小预览器也好,把本机实例的目录和数据库路径展示清楚也好,本质上都在压缩确认成本。
对开发者来说,这种成本不是宏大叙事里的“生产力跃迁”,而是每天会碰到的几分钟、十几分钟。累积起来,反而比一次大型功能更新更实在。
直接受益的人是谁,不适合的人又是谁
新线索还补上了旧稿里比较欠缺的一点:受众边界。
最直接受益的人包括:
- 同时运行多个 Datasette 实例的开发者
- 经常在测试库、临时库、正式数据镜像之间切换的人
- 做 Datasette 插件开发、演示和数据发布的人
- 本地机器上会同时保留多个试验项目的人
对这些人来说,收益很具体:
- 少猜端口
- 少翻终端历史
- 少在
/tmp和项目目录里找错数据库 - 更快判断问题来自核心服务还是某个插件
但它的限制也同样明确。datasette-ports 解决的是“我这台机器上跑了什么”,不是“我的服务怎么统一治理”。如果环境切到远程服务器、容器编排、Kubernetes 或团队协作场景,问题会变成权限、日志、挂载卷、服务发现和生命周期管理。那时你需要的是 observability 和运维体系,不是一个本机排查小工具。
这一点对旧稿也是重要补强。谈 AI 接管边角料工作时,很容易把结论说得太大;而 datasette-ports 0.3 这条线索提醒我们,真正能落地的往往是局部问题、局部收益、局部人群。它很好用,但只在合适的语境里好用。
更现实的判断:AI 和开发工具的结合,短期内会先集中在这些小而准的地方
把 YAML 预览器和 datasette-ports 放在一起,能看到一条更清楚的脉络。
开发者工具接下来一段时间里,最容易稳定产生价值的,不是让 AI 一口气包办完整系统,而是让它参与制作或强化这些小而准的辅助能力:
- 更快生成一次性内部工具
- 把已有系统命令包装成带业务上下文的视图
- 减少定位、确认、比对、格式转换这类杂事
- 把原本依赖个人经验的排查动作产品化
这也是新来源对旧稿最扎实的补充:它提供了一个非口号式的参照案例。真正留下来的功能更新,往往不是更大,而是更贴近“我现在就会被它省下几步”。
Simon Willison 的做法有连续性。他不是在展示 AI 多强,也不是在堆砌一个大平台,而是在持续填平开发流程里的小坑。YAML 预览器是一个坑,datasette 本地实例识别又是另一个坑。工具不大,但都对准了注意力最容易被浪费的位置。