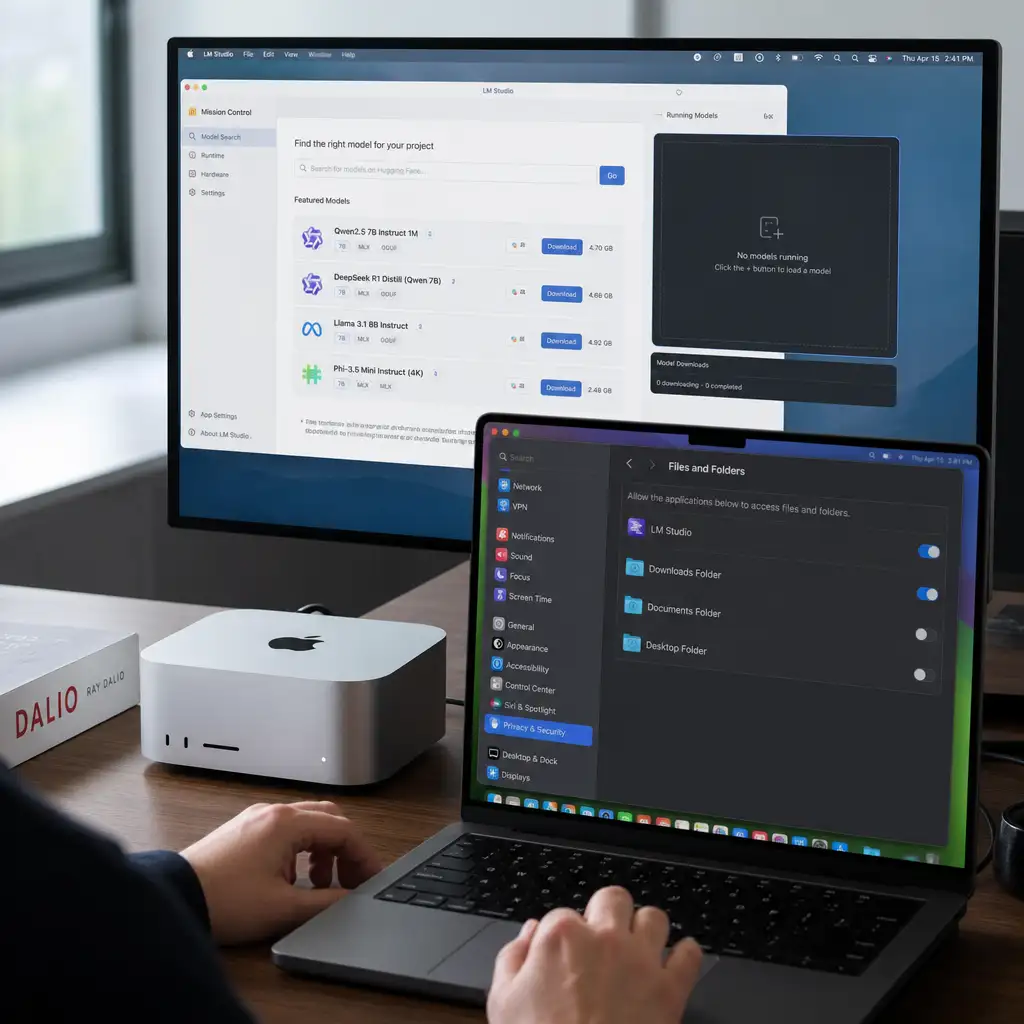
Osaurus 这件事最反常的地方,不是它又接了很多模型,而是它把 AI 的位置往回拽了一步:从云端 API,拉回到你的 Mac。
它只面向 Apple 生态,是一个开源的 Mac AI 控制层。更准确说,它是一个 harness:把本地模型、云端模型、文件、工具和工作流接到同一个入口里。
这听起来不如“新模型发布”刺激,但可能更接近应用层的真实战争。模型能力继续追平,入口、上下文和执行权限开始涨价。
Osaurus 做的不是模型,是本机 AI 控制层
Osaurus 不是新基础模型,也不是单纯聊天框。
它做的是连接和调度:用户可以在本地模型和云端模型之间切换,也可以让 AI 访问本机文件、工具和工作流。
目前它支持的范围很宽。本地或本机托管一侧,包括 MiniMax、Gemma、Qwen、Llama、DeepSeek 等;云端一侧,包括 OpenAI、Anthropic、Gemini、xAI/Grok,也能接 OpenRouter、Ollama、LM Studio 等服务。
它还支持 MCP,内置 20 多个原生插件,覆盖 Mail、Calendar、Browser、Filesystem、Git、PPTX、XLSX、Search、Fetch 等。最近还加了语音能力。
压缩看,大概是这张表:
| 问题 | Osaurus 的做法 | 读者该怎么理解 |
|---|---|---|
| 它是什么 | Mac 上的 AI harness / 控制层 | 不是基础模型,是入口层 |
| 能接什么 | 本地模型 + 云端模型 | 重点在切换、编排和调用 |
| 数据在哪里 | 记忆、文件、工具尽量留在本机 | 隐私叙事更强,但不等于绝对安全 |
| 怎么控风险 | 硬件隔离的虚拟沙盒 | 限制 AI 访问范围,降低误触风险 |
| 谁能用 | Apple-only | 不能泛化到所有 PC 用户 |
它和 OpenClaw、Hermes 这类更偏开发者的工具有相似之处,但路线不完全一样。Osaurus 想做得更桌面、更消费级,少一点命令行,多一点普通 Mac 应用的手感。
这也解释了它为什么要强调沙盒。AI 一旦能读文件、查日程、动浏览器,就不再只是“回答问题”。它开始碰你的工作现场。
本地运行能减少一部分数据外传焦虑。硬件隔离的虚拟沙盒也能限制 AI 的活动范围。但这不是护身符。只要 AI 能访问文件和工具,就必须回答三个问题:它能看什么、能改什么、出错谁负责。
官网称 Osaurus 上线近一年下载量超过 112,000 次。这个数字只能说明有关注度,不能等同于活跃用户、付费用户或商业成功。
普通用户先别急,高配 Mac 和敏感行业更该看
本地 AI 的现实门槛很硬。
原文给出的硬件要求很直接:跑本地模型,至少约 64GB RAM;如果是 DeepSeek V4 这样的大模型,创始人建议约 128GB RAM。
这基本把普通 Mac 用户挡在外面。很多 MacBook Air、入门款 Mac mini 用户可以围观,可以试轻量模型,但别指望它马上变成日常主力。
更现实的决策是分人群看:
| 用户类型 | 现在该怎么做 | 不该期待什么 |
|---|---|---|
| 普通 Mac 用户 | 观望,或只试轻量、本地优先的小任务 | 别期待本地 AI 立刻替代 ChatGPT、Claude |
| 高配 Mac 用户 | 可以尝试把文件整理、表格、邮件、代码等流程接进去 | 别忽略权限设置和沙盒边界 |
| 开发者 / 工具团队 | 研究它的 MCP、插件和工作流编排方式 | 别只盯模型接入数量 |
| 法律、医疗等隐私敏感行业 | 可以评估本地优先方案,先从低风险资料处理试点 | 别把“本地”当成合规结论 |
最有动作价值的是两类人。
一类是高配 Mac 用户和开发者。如果手里已经有 64GB 或 128GB 内存的机器,Osaurus 值得试。不是为了炫本地大模型,而是看它能不能把文件、邮件、日程、代码、浏览器这些东西串起来。
另一类是隐私敏感团队,比如法律、医疗。它们未必不想用 AI,而是不敢把客户文件、合同、病例材料随便丢进云端黑箱。本地优先不解决全部合规问题,但至少把“数据必须出门”这件事变成可谈判选项。
采购上也会有影响。对这类团队来说,问题不只是买不买 Osaurus,而是要不要把下一批工作站配置往 64GB/128GB RAM 推。AI 本地化不是免费午餐,它会直接落到硬件预算上。
这也是我不太买账“本地 AI 马上改写云端 AI”的原因。云端仍然更强、更省心,也更适合大多数用户。Osaurus 更像一个早期分层信号:高端设备、专业工作流、敏感数据场景先长出来。
真正值钱的,是谁拿到电脑上的执行入口
我更在意 Osaurus 押的不是“哪家模型最强”,而是“模型之上的控制层”。
这有点像早期 PC 时代。芯片很重要,但日常权力最后落在操作系统、文件系统、默认应用和入口分发上。谁贴近工作流,谁更容易收租。
今天的大模型也在往这条路走。用户不会天天研究参数表。用户只会问:它能不能读我的文件,懂我的上下文,帮我改表格、发邮件、跑代码、查日程,而且别乱碰敏感数据。
“天下熙熙,皆为利来。”放在这里并不虚。云厂商要 token、要算力利用率、要用户留在云端;本地 AI 工具要入口、要信任、要工作流粘性。嘴上都讲智能,账本上写的是控制权。
Osaurus 这类产品的意义,不是立刻减少数据中心需求。现在还没有证据能支撑这种判断。
它真正推动的是另一件事:把隐私、成本和平台控制权重新摆上桌。
接下来最该看三件事。
一是本地模型的“每瓦智能”能不能继续提高。如果小模型足够能干,本地 AI 才会从高配玩家走向更多专业用户。
二是沙盒和权限控制能不能做得足够细。AI 控制电脑时,体验和安全天然打架。权限太松,风险上升;权限太紧,工具变钝。
三是 Apple 会不会亲自下场。Apple-only 是限制,也是护城河。统一硬件、系统权限和安全框架,确实适合做本机 AI 控制层。
但平台方的阴影也在这里。第三方先做入口,平台再把能力收进系统,科技史里见过太多次。创业公司最难的不是证明需求存在,而是证明自己能守住入口。
所以 Osaurus 还不能被吹成本地 AI 的胜利。它更像一个指针,指向模型商品化之后的下一层竞争:谁能安全、稳定、低摩擦地调度用户电脑上的上下文和工具。
这件事小,但刀口准。