Anthropic 给 Mythos 的说法一直很克制,也很诱人:它能发现真实、困难的安全漏洞,所以不能轻易开放。
这句话听着像安全责任,也像老牌厂商最熟悉的护城河叙事。能力越稀缺,越适合被包装成神秘资产。
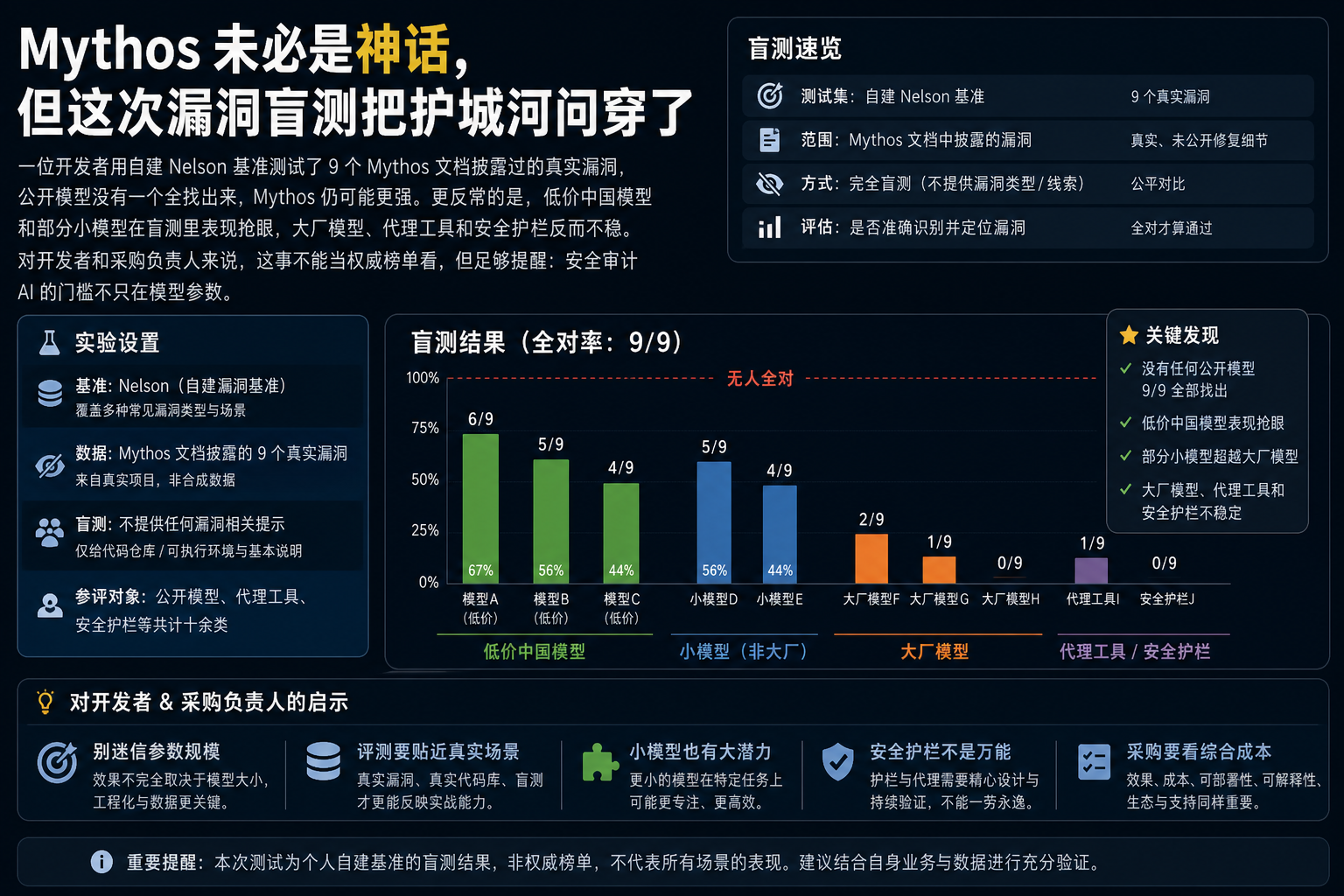
现在,有开发者用自建 Nelson 基准做了一次小规模拆解:拿 Mythos 文档里披露过的 9 个真实漏洞,找修复前代码,让公开模型在盲测里自己找洞。
结果不适合写成排行榜。样本只有 9 个,多数模型基本只跑一次,还受超时、预算、崩溃重试影响。但它已经问到了关键处:Mythos 的优势,到底来自模型本身,还是来自工具链、提示设计和 agent 系统?
这次测的不是榜单,是 Mythos 的可复现性
这次测试的语料不是玩具题,也不是让模型复述已知 CVE。
漏洞来自 Mythos 文档披露过的真实发现。作者取了修复前代码,用 Opus 做 vetting,并有人类抽查。所有漏洞大概率都在各模型知识截止之后,降低了“背答案”的可能。
测试方式也很直接:给模型相关文件、仓库代码和基础工具,不告诉漏洞位置,只让它审计。
| 项目 | 做法 | 现实限制 |
|---|---|---|
| 漏洞来源 | Mythos 文档披露的真实漏洞 | 当前只有 9 个案例 |
| 测试材料 | 修复前代码 | 依赖作者取样和 vetting |
| 测试方式 | 盲找漏洞 | 多数模型基本只跑一次 |
| 工具条件 | 基本相同文件和工具 | Claude 因成本使用 Claude Code |
| 结论边界 | 看公开模型能否复现 Mythos 发现 | 受超时、预算、崩溃重试影响 |
最硬的一点是:公开模型没有找到 Mythos 找到的全部漏洞。Mythos 仍可能确实更强。
但另一点也不能忽略:Opus 在被提示到相关区域后,能理解这些漏洞。这说明公开模型不是完全看不懂。差距更像出在搜索、定位和验证,而不是单纯“智商不够”。
这对安全团队很要命。
会解释漏洞,和能在巨大代码库里主动摸到漏洞,是两种能力。前者像读病历,后者像查病因。安全审计真正花钱的地方,恰恰在后者。
反常点:便宜模型能打,护栏也能拖后腿
这组结果最有价值的部分,不是谁第一。
样本太小,运行也不够稳定。把它当采购榜单,是给自己挖坑。
更值得看的是几个反常点。
| 现象 | 能说明什么 | 不能说明什么 |
|---|---|---|
| Qwen 3.6、MiMo、DeepSeek 表现突出 | 在这类安全盲测里,低价模型的命中率和性价比值得认真看 | 不能推出中国模型全面领先 |
| Gemma 4 等小模型偶尔越级 | 参数规模不是唯一变量 | 不能证明小模型稳定可替代大模型 |
| Gemini、Mistral、Haiku/Sonnet 槽点明显 | 大厂品牌不等于安全审计可靠 | 不能用一次测试否定模型整体能力 |
| Google Antigravity CLI 多次拒绝漏洞分析 | 安全护栏可能影响安全研究 | 不能说明护栏本身没有必要 |
Antigravity CLI 这个例子最刺眼。它在 9 个案例里 8 次拒绝分析“可利用安全漏洞”。
从合规角度看,这可能是谨慎。从安全研究角度看,就是工具在关键场景失职。
“削足适履”很贴切。为了避免帮助攻击者,产品把防守者的手也捆住了。安全护栏该像刹车,不该像拔方向盘。
这里的矛盾会越来越常见。厂商想卖安全产品,又怕产品真的谈安全细节。结果就是:攻击者未必被拦住,防守者先被流程拦住。
开发者该怎么做?别只试一次模型问答。要把模型放进真实仓库,给同一批历史漏洞跑盲测,看它能不能独立定位、给出可验证路径、少报废话。
技术负责人也别急着签“安全 agent”大单。更稳的动作是先做小样本内部基准:选自家修过的漏洞,隐藏 patch,统一预算,记录命中、误报、耗时和拒答率。采购可以延后,基准要先建。
Mythos 的优势,可能是系统工程,不是神力
我不太买账的是,把 Mythos 讲成一个单独更聪明的模型。
安全漏洞发现不是普通问答。它要读代码、跨文件追踪、理解运行时状态、构造攻击路径。还可能需要调试器、fuzzing、污点分析、反复试错和长时间搜索。
模型只是其中一个部件。
这次 Nelson 基准的 harness 很朴素。Mythos 很可能使用更复杂的工具链。如果它能跑程序、打断点、生成输入、验证崩溃,那它赢公开模型并不奇怪。
赢的可能是系统工程,不只是模型参数。
这也是判断 AI 安全审计产品时最容易被遮住的地方。厂商喜欢展示“发现了一个洞”。用户真正该问的是:
- 同样预算下能跑几轮?
- 误报谁来筛?
- 能不能接进现有代码库、CI 和 issue 流程?
- 护栏会不会在关键时刻拒绝工作?
- 结果能不能复现,而不是只在 demo 里闪光?
铁路早期也爱讲机车多快。后来真正拉开差距的是调度、轨距、维修和账本。AI 漏洞发现也会走到这一步。
神话会退潮,工程会留下。
所以这次测试的答案不是“Mythos 被打脸”,也不是“公开模型追平”。更准确的说法是:Mythos 可能领先,但领先来源还没被解释清楚;公开模型已经逼近到足以让这个问题变得尖锐。
接下来最该观察的不是新榜单,而是三件事:更多真实漏洞样本、可重复运行的测试 harness、以及带工具链的 agent 对比。没有这些,所有“神力”都要先打折。