聊天机器人最别扭的地方,往往不是不聪明。
而是它太像值班客服:你说完,它再想;它说完,你再插嘴。对话被切成一段一段,像在排队取号。
Mira Murati 的 Thinking Machines 这次把牌亮了一点。TML-Interaction-Small 出来后,之前那个“押注实时多模态”的判断不再只停在方向上。它有了具体模型、具体评测,也有了一个更清楚的靶子:传统 VAD 式轮次交互。
但别急着把它写成胜利宣言。
目前能看到的是一次技术预览和能力展示,不是大规模产品落地。方向更可信了,验证还没完成。
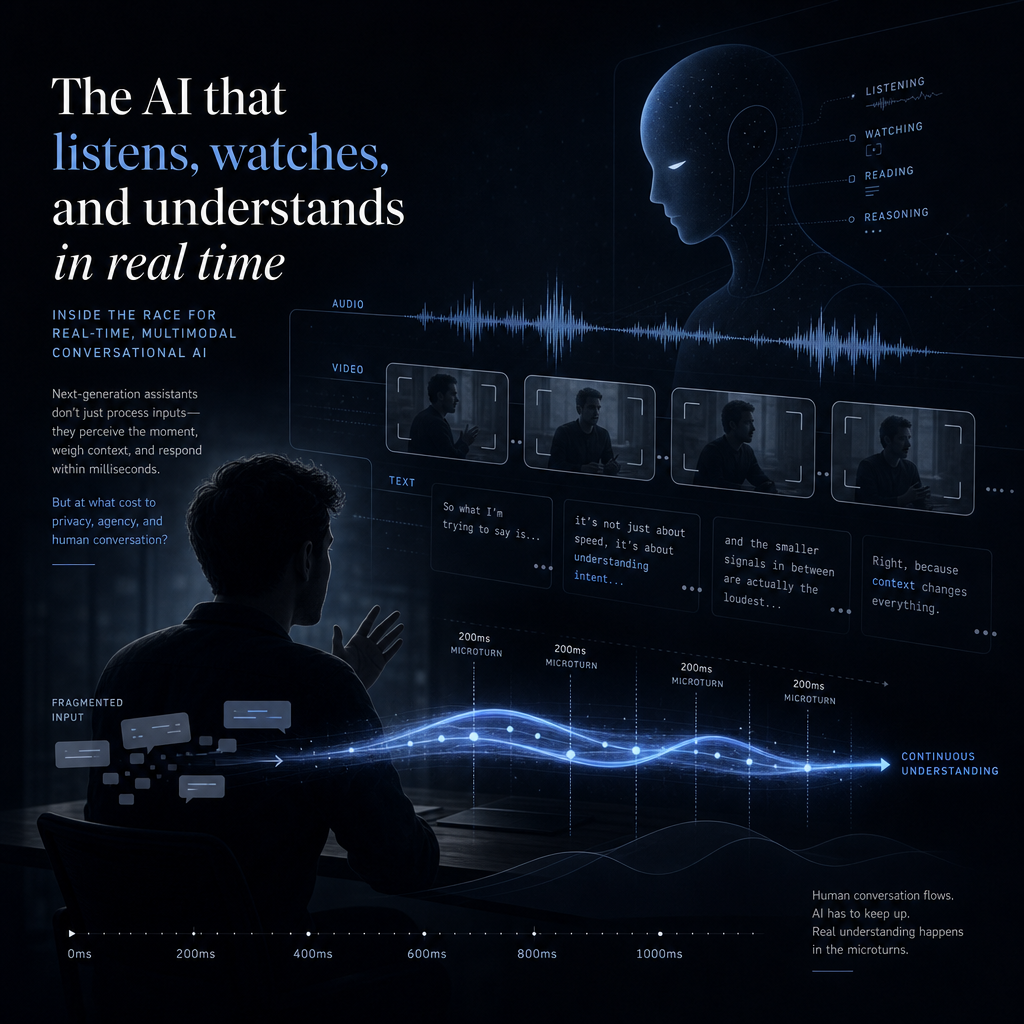
这次补上的硬信息:模型开始管“时间”了
TML-Interaction-Small 是一个 276B 参数的 MoE 模型,推理时约 12B active。它主打原生实时交互:音频、图像、文本一起进入模型,采用 encoder-free early fusion,音频和图像处理压到 200ms 以下,并用 time-aligned microturns 持续对齐时间。
相比此前外界只能看到 Thinking Machines 押注实时多模态,这次材料补上了三块信息:
| 问题 | 现在知道了什么 | 意味着什么 |
|---|---|---|
| 模型路线 | 276B MoE,12B active | 不是小模型玩具,而是大容量、稀疏激活路线 |
| 交互方式 | 200ms 级微回合,音视频文本早融合 | 模型不只等用户说完,而是持续感知场景 |
| 评测重点 | TimeSpeak、CueSpeak、RepCount-A、ProactiveVideoQA、Charades | 评测从“答得对不对”转向“时机准不准” |
它在 BigBench Audio、IFEval、FD-bench 等基准上压过 GPT-Realtime-2 和 Gemini 3.1-Flash。这个结果可以看,但不要只看跑分。
更有价值的是 Thinking Machines 自己补的几类评测。
TimeSpeak 看模型能不能按用户指定时间开口,比如每 4 秒提醒一次呼吸。CueSpeak 看它能不能在合适时机插入,比如用户切换语言时即时纠正。RepCount-A 看视频里重复动作的持续跟踪和及时计数。ProactiveVideoQA 看答案只在某个时刻出现时,模型能不能抓住那个窗口。Charades 则测 temporal action localization,也就是动作开始、结束时能不能及时说出来。
这些测试指向同一个问题:AI 不能只会回答,还要懂节奏。
这就是这次材料真正的新东西。
VAD 没死,但不该再当交互大脑
过去的实时语音产品,很大程度靠 VAD,也就是语音活动检测。
用户停顿,系统接管。用户开口,系统打断。工程上简单、便宜、可控,也容易上线。
问题是它不够像人。
人类对话不是靠“静音超过几百毫秒”判断轮到谁说话。我们会听语气,看表情,猜意图,也会在对方没讲完时轻轻补一句。VAD 能判断声音有没有,但很难判断话该不该接。
TML-Interaction-Small 不是把 VAD 一刀砍死。现实部署里,VAD 仍然会作为降噪、安全阀、成本控制层存在。
但它把 VAD 从“交互大脑”打回了“工程部件”。
这个变化有点像早期网页从整页刷新走向 AJAX。不完全一样,但用户体感类似:底层协议还在,页面还在,真正变化的是交互从一页一页翻,变成局部、连续、可响应。
实时 AI 也在走这条路。不是把 LLM 接上麦克风和摄像头就完事,而是让模型在连续时间里听、看、判断、行动。
GPT-4o 当年的“Her”式演示点燃过这种想象:声音自然,能打断,像一个真正陪你说话的人。但那更像舞台时刻。Thinking Machines 这次也还没有给出开放范围、真实用户规模、推理成本、稳定性这些答案。
所以判断要压住:它证明了路线更像样,还没证明产品已经过关。
真正受影响的,是实时产品和 Agent 开发者
普通用户短期内未必会立刻换一个助手。
最先被影响的是两类人:做实时语音/视频产品的团队,以及做多模态 Agent 的开发者。
过去的产品流程大多很规整:
- 语音助手.唤醒、识别、理解、回复。
- 多模态应用.上传图片或视频、分析、返回答案。
- Agent.接任务、规划、调用工具、输出结果。
这些流程都有一个共同假设:用户和模型轮流占用时间。
原生交互模型拆的就是这个假设。
视频陪练不该等用户做完一组才总结,它应该边看边纠正。会议同传不该等整句结束才翻译,它要在不误解语义的前提下持续输出。工业巡检不该只回答“刚才发生了什么”,而要在关键动作出现时提醒。Agent 也不该把“我正在搜索”“我正在思考”切成尴尬播报,而应在后台行动、前台协作。
这听起来诱人,落地时很难。
因为连续听看会带来更高算力压力。更复杂的权限边界。更难解释的误触发。更烦人的打断体验。
一个随时能插话的 AI,如果不会看时机,会比笨一点的聊天机器人更讨厌。
模型看着更强,产品反而更容易露怯。
押对方向,不等于赢下产品
我更愿意把 Thinking Machines 这次发布看成一次“路线补证”。
此前的问题是:Mira Murati 的新公司押注实时多模态,但外界没法判断它到底是在讲愿景,还是已经摸到了产品骨架。TML-Interaction-Small 至少把骨架露出来了一部分。
它补强了旧判断里的积极部分:实时多模态不是一个包装词,它确实正在从输入输出层,进入模型结构和评测体系。
它也缩窄了旧判断里的怀疑点:怀疑不再是“有没有东西”,而是“这东西能不能稳定、便宜、可控地给真实用户用”。
这两个问题差很多。
实验室里做到 200ms 微回合是一回事。把它放进会议、客服、教育、陪练、工业现场,让它每天处理脏数据、噪声、口音、遮挡、误触发、权限边界,是另一回事。
“天下熙熙,皆为利来。”这句老话放在这里很合适。谁能把连续交互做成稳定入口,谁就能拿到更高频、更贴身、更难替代的用户关系。语音助手、视频应用、陪练、客服、教育工具,都可能被重新切一刀。
但利在哪里,成本也在哪里。
实时交互的竞争不会只看谁的模型更会说。它会看四件事:
- 延迟能不能低到用户忘掉机器存在;
- 成本能不能低到产品敢常开;
- 打断能不能准到不惹人烦;
- 权限能不能清楚到用户愿意让它一直听、一直看。
这才是接下来该看的变量。
Thinking Machines 这次少见地把问题推到了正确位置:AI 的难点不再只是生成答案,而是进入人的时间流。进入时间流,就要学会分寸。
能听会说只是热闹。知进知退,才是门槛。