一名开发者近日记录了在 24GB 内存 M4 MacBook Pro 上运行本地大模型的测试过程。结果并不接近云端 SOTA 模型,但在 LM Studio 中运行 Qwen 3.5-9B Q4_K_S,已经能完成部分代码辅助、研究和规划任务,且无需联网。
这件事真正重要的地方,不是消费级 Mac 突然变成“随身数据中心”,而是本地模型开始进入一个开发者能日常试用的区间:隐私更可控、离线可用、没有按月订阅账单。它不重要的地方也很清楚——这不是权威基准,更不是本地模型战胜云端模型的证据。
24GB M4 上能跑,但配置并不轻松
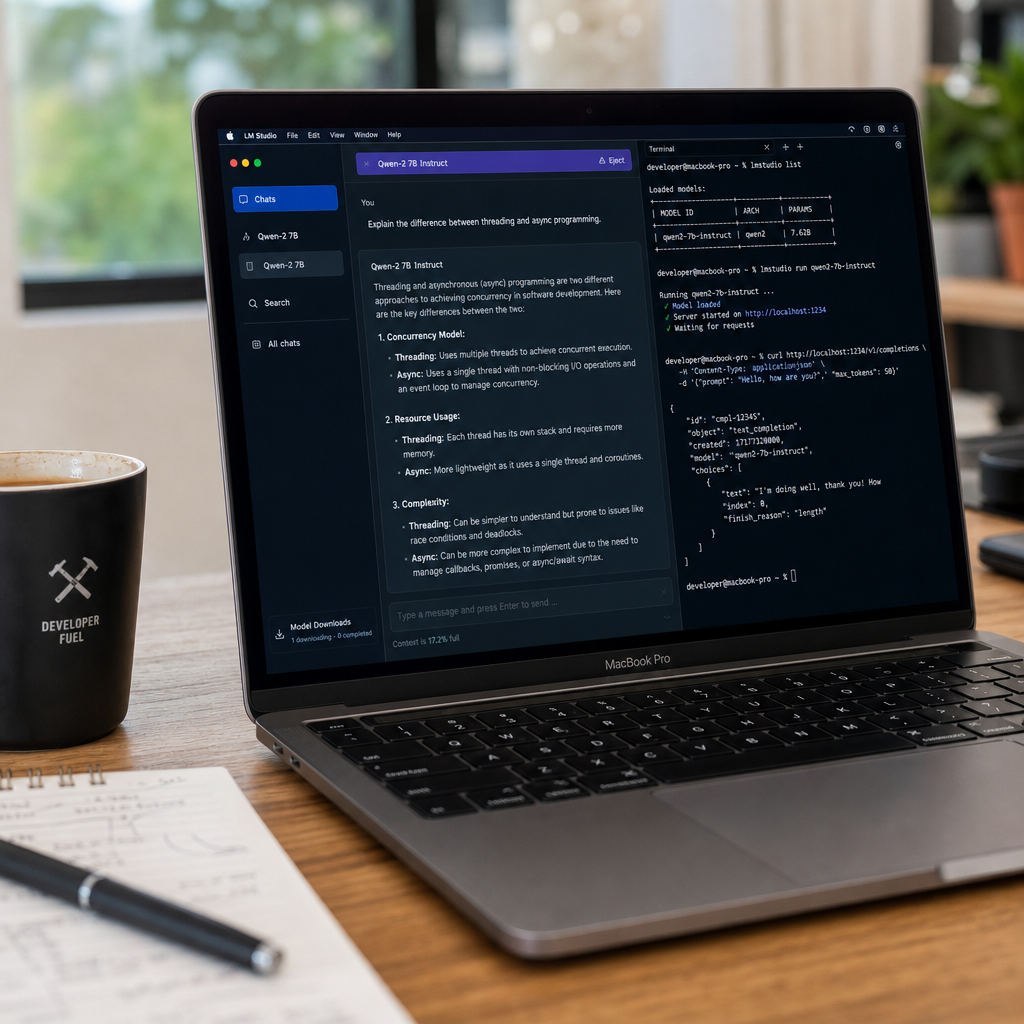
作者的硬件锚点是 M4 MacBook Pro、24GB 内存,本地运行环境选择 LM Studio。相比 Ollama、llama.cpp,LM Studio 的优势是上手相对直观,但模型选择、量化版本、上下文长度、thinking 开关和采样参数仍然会影响体验。
在这次个人测试中,Qwen 3.5-9B Q4_K_S 是表现最平衡的一档:约 40 tokens/s,开启 thinking,128K 上下文,并支持工具调用。作者还通过 pi 和 OpenCode 接入本地 LM Studio 服务,把它用于代码仓库里的实际任务。
| 模型 / 方案 | 测试结果 | 判断 |
|---|---|---|
| Qwen 3.5-9B Q4_K_S | 约 40 tokens/s,128K 上下文,工具调用可用 | 目前最接近“日常可用” |
| Qwen 3.6 Q3、GPT-OSS 20B、Devstral Small 24B | 能装入内存,但实际不可用 | 纸面能跑不等于体验能用 |
| Gemma 4B | 运行顺畅 | 工具使用能力偏弱 |
| 云端 SOTA 模型 | 长任务、复杂代理能力更强 | 仍是能力上限所在 |
这个对照说明了一个容易被忽略的条件:本地模型不是只看“能否塞进内存”。还要给系统、浏览器、编辑器和一堆 Electron 应用留余量。对开发者来说,卡顿、循环、工具调用失败,都会把省下的订阅费变成调试成本。
Qwen 3.5-9B Q4 的价值在辅助,不在放手代理
作者给出的两个例子很能说明边界。一次是升级 Elixir linter Credo 后出现警告,模型正确识别出 length(list) > 0 应改成 list != [],随后完成 4 处并行编辑。这个场景简单、局部、可验证,本地模型用得顺手。
另一次是处理 dependabot PR 的 git rebase 冲突。模型准确判断应保留 sentry 13.0.1 和 tailwind 0.4.1,但在执行时没有先编辑冲突文件,直接 git add 并继续 rebase,随后因编辑器打开导致 OpenCode 卡住。它理解了问题,却没稳定完成操作链。
这正是本地小模型当前最现实的位置:适合作研究助手、橡皮鸭、命令行和语言细节检索工具;不适合被要求一次性构建复杂应用,或长时间自主推进多步骤代理任务。云端模型也会出错,但更强模型在长上下文规划、纠错和工具链连续执行上仍有优势。
受影响的是想降云依赖的开发者
这类配置最适合两类人:一是经常在飞机、弱网或内网环境工作的开发者;二是对代码、笔记、业务材料上云有顾虑的技术用户。LM Studio 在本机开放 OpenAI 兼容接口后,pi、OpenCode 这类工具可以直接接入,迁移成本不算高。
但“本地”不等于零成本。电力、硬件折旧、调参时间都是真成本;模型训练的环境代价也不会因为推理发生在笔记本上而消失。更现实的观察点,是 24GB 这类消费级内存配置能否稳定支撑 9B 到 14B 量级模型的工具调用,以及 LM Studio、Ollama、llama.cpp 等工具能否减少模板、缓存量化、上下文配置上的手工折腾。
对今天想动手的人,结论可以更直接:如果目标是替代 ChatGPT、Claude 或 Gemini 的高强度编程代理,暂时别高估它;如果目标是离线查资料、解释报错、改小片段代码,24GB M4 Mac 已经能给出一个可用但需要看管的答案。