一个单目视频,只有一个视角,却想还原动态物体的完整4D形态。
这就是Lift4D这篇工作的切口。它处理的是野外单目视频,不是多机位棚拍,也不是可控扫描。输入是一段普通视频,输出目标是动态物体的完整几何、外观和随时间变化的形变,甚至包括相机没看见的区域。
这件事有意思的地方在于,它没有把问题说成“视频版单图生3D”。它更像是在承认一个现实:单靠视频里的可见像素,很多东西就是缺的。背面、遮挡处、剧烈形变后的细节,都需要先验来补。
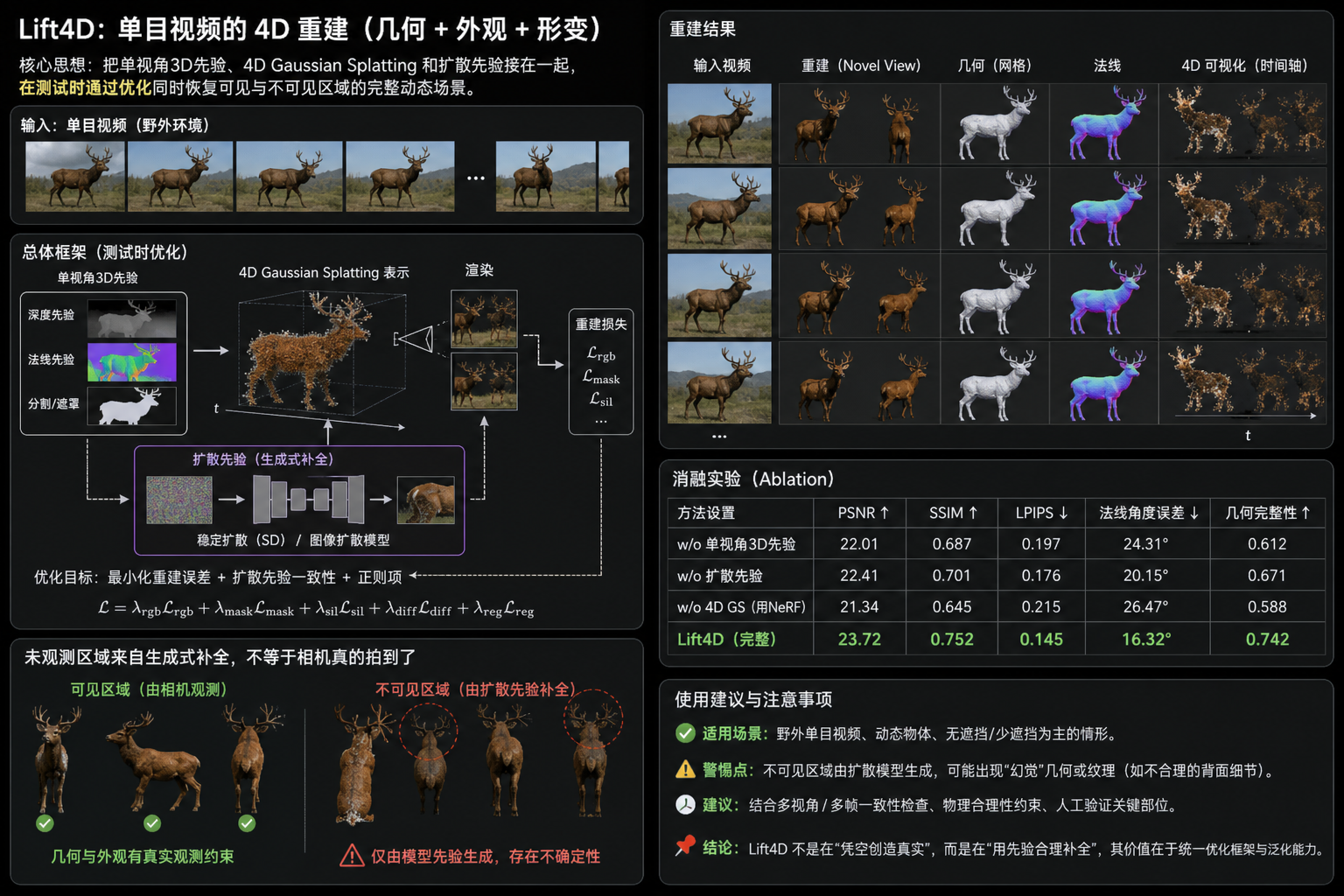
我更在意的是这条主线:Lift4D把单视角3D模型、4D Gaussian Splatting和新视角扩散先验拧到一起,用测试时优化去协调它们。它补的是现有4D重建里最难受的短板:遮挡、大形变和未观测区域。
单目4D重建难在“看不见”,不是只难在“算不准”
单目4D重建的输入很弱。一个摄像头,只给一条时间线。物体转过去时,背面没有观测;手臂、衣物、工具互相挡住时,被遮住的区域也没有观测。
这和多视角重建不是一个难度。多视角至少可以用不同相机互相补洞。单目视频里,很多信息从采集那一刻就缺席了。
更麻烦的是动态物体会变形。非刚性运动会让同一个点在不同帧里难以稳定对应。人、动物、衣服、软体物体都容易出现这类问题。
所以,传统做法常卡在两头:只依赖视频重投影,容易在遮挡和背面处塌掉;逐帧做3D预测,又容易每帧长得不一样。
Lift4D的判断是:不能只靠一种信号。可见区域要对齐视频,未见区域要借助生成式先验,时间一致性还要靠4D表示和形变建模来兜住。
这对研究者的影响很直接。做动态Gaussian Splatting或4D资产生成的人,不能只比较可见视角渲染效果,还要看遮挡后再出现时,几何和纹理是否能接上。
Lift4D的办法:先给逐帧3D,再统一到4D高斯
Lift4D先用image-to-3D DiT给每一帧生成3D初始化。但它没有让每一帧独立生成。
它引入了因果潜变量传播。当前帧的3D latent由新噪声和前一帧去噪后的latent混合得到。这样做的目标很明确:让逐帧3D预测在时间上更连续,减少“每帧各长各的”问题。
接着,系统把逐帧Gaussian splats整合成统一的canonical Gaussians。也就是先建立一个规范空间,再用形变去解释每一帧的动态变化。
形变由两组稀疏节点建模。一组负责几何运动,另一组负责细粒度外观形变。这个拆分很重要,因为动态物体不只是位置在动,表面纹理、褶皱、局部外观也会变化。
优化阶段才是Lift4D和普通4DGS路线拉开差距的地方。它使用遮挡感知外观损失,只在可见像素上对齐输入视频;对不可见区域,则借助遮挡修复帧、随机新视角渲染和新视角扩散先验来提供约束。
可以把它理解成三类信号的分工:
| 信号来源 | 解决什么问题 | 现实边界 |
|---|---|---|
| image-to-3D DiT逐帧初始化 | 给单帧提供3D形状和外观先验 | 单帧预测容易不稳定,需要时间约束 |
| canonical Gaussians + 稀疏形变节点 | 把逐帧结果统一成可播放的4D表示 | 大形变下仍可能依赖优化质量 |
| 新视角扩散先验 | 给背面和遮挡区域提供补全约束 | 补全是生成式猜测,不是真实观测 |
这套组合的价值不在某个模块单独多强,而在于分工清楚。看得见的地方尽量贴视频,看不见的地方交给先验,时间变化交给4D高斯和形变节点。
对开发团队来说,这会影响工具选择。如果团队现在用4DGS做动态资产,可以把Lift4D看作一个研究基线:重点对比遮挡恢复、非刚性运动和新视角一致性,而不是只看正面渲染是否好看。
但如果目标是上线级工具,动作要更保守。材料里没有给出运行速度、开源状态、数据规模或具体量化指标,工程团队不适合直接据此迁移管线。更现实的做法是先观望实现细节,或只把它放进离线资产生成、预览和研究验证环节。
改进很明确,边界也很明确
论文声称Lift4D在合成和野外视频上优于既有4D重建基线,尤其是在严重遮挡和非刚性运动场景中。这个结论和它的方法设计是对得上的。
过去很多方法在物体转身、肢体交叠、衣物摆动时容易出现几何断裂、纹理拖影或背面空洞。Lift4D至少给出了一条更完整的处理路径:用单视角3D先验起步,用4D高斯维持动态一致,再用扩散先验补不可见区域。
但“完整”不能读成“真实恢复”。
扩散先验补出的背面纹理、被挡细节和新视角外观,本质上是条件生成。它可能合理,也可能幻觉。相机没有拍到的东西,模型不能凭空变成事实。
这决定了它的适用边界。
| 使用场景 | 更适合怎么用 | 要避开的误解 |
|---|---|---|
| 影视预览、游戏资产草模、研究可视化 | 用来生成更完整的动态物体初稿 | 不要把补全细节当作真实扫描 |
| 3D/4D重建研究 | 作为遮挡和大形变场景下的对比路线 | 不要只看单视角重投影效果 |
| 工业检测、测量、取证 | 目前应谨慎,仍需真实多视角或传感器数据 | 不要用生成式补全替代证据 |
接下来最该看的不是一句“效果更好”,而是几个硬变量。
测试时优化要多久?复杂视频里只处理单个动态物体,还是能稳定处理多物体遮挡?扩散补全在不同类别、不同材质、不同动作幅度下是否一致?如果实现不开源,复现成本又会多高?
这些问题没有答案前,Lift4D更像研究前沿的一次有效拼装,而不是马上可采购的生产工具。
它真正推进的是判断框架:单目4D重建不再只问“能不能从视频拟合出来”,还要问“看不见的部分由谁补、补得有多可信”。
回到开头那个问题:一个视角能不能重建完整动态物体?Lift4D给出的回答是,可以更接近,但代价是引入生成式先验。见者求真,未见者只能求可信。