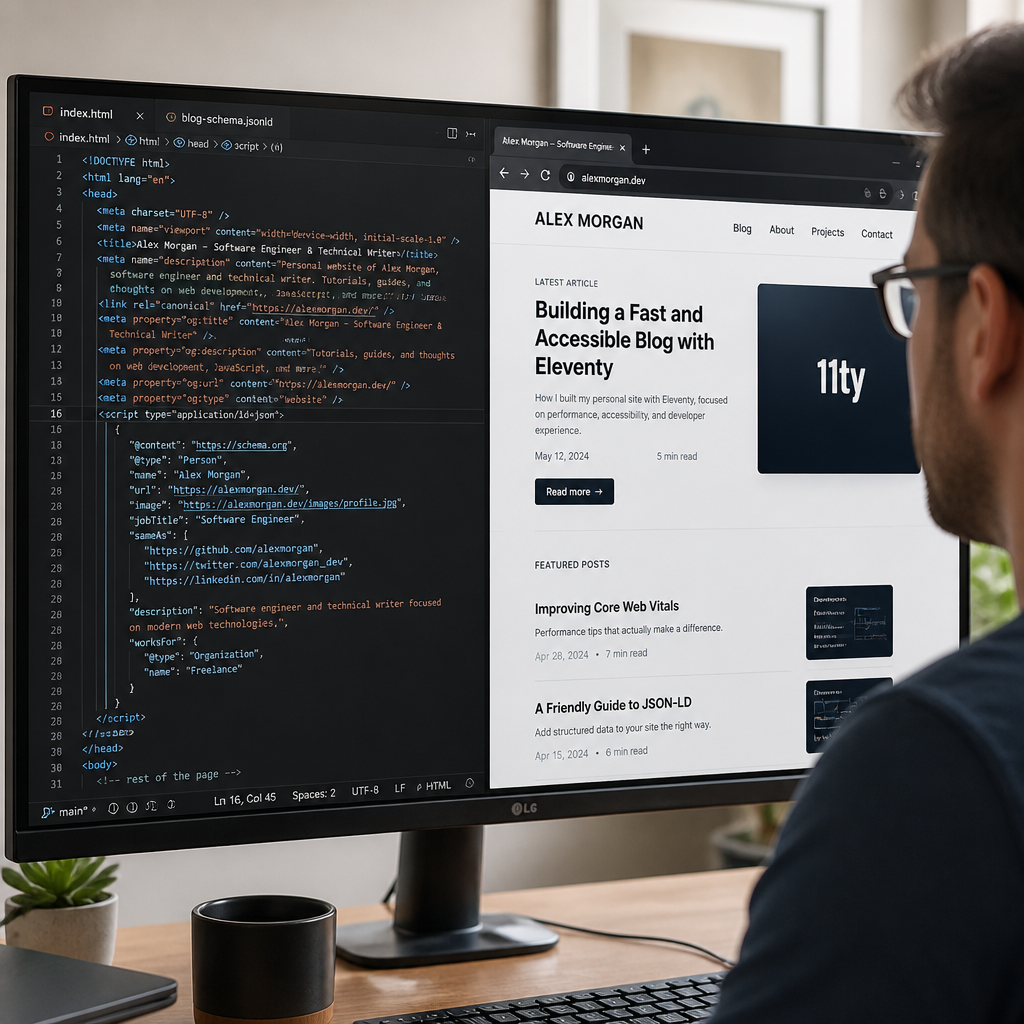
个人网站作者 Ethan Hawksley 发布了一篇面向站长和技术博客维护者的 JSON-LD 实用说明,核心是如何用 Schema.org 描述个人、网站、页面、博客文章和项目页。它不是新标准发布,也不是搜索引擎规则更新,但对维护作品集、技术博客的人很实用:结构化数据应当服务于“让机器看懂页面”,而不是被包装成万能 SEO 技巧。
JSON-LD 要放在页面 head 中,使用 <script type="application/ld+json">。浏览器不会把它当 JavaScript 执行,Googlebot 等爬虫会解析其中的 @context、@graph、@type 和 @id。关键判断是,个人网站需要的是一组少而稳的节点,而不是把 Schema.org 的类型表搬进源码。
个人网站最该保留的是少数核心节点
JSON-LD 的价值在于建立清晰关系。@context 通常指向 https://schema.org,@graph 放多个节点,@id 最好使用稳定 URL 加 hash,例如 https://example.com/#person。同一节点可跨页面复用,但单页爬虫、部分 LLM 抓取器未必会合并多页信息,所以非首页也不能只留一个空壳。
| 节点 | 放在哪里 | 判断 |
|---|---|---|
| WebSite | 首页完整,其他页面精简 | 描述站点名称、URL、发布者;非首页保留基本信息即可 |
| Person | 几乎每页都应包含 | 个人网站的作者、发布者、身份锚点,sameAs 对消歧很有用 |
| WebPage / ProfilePage / CollectionPage | 按页面类型使用 | WebPage 描述 HTML 页面;ProfilePage 适合首页或关于页;CollectionPage 适合博客列表、链接页 |
| Blog / BlogPosting | 博客首页与已发布文章 | BlogPosting 描述文章内容,不应和 WebPage 混为一谈 |
| SoftwareApplication | 项目展示页 | 适合软件项目、开源工具、应用介绍页 |
| BreadcrumbList | 非首页 | 帮助搜索结果显示更清楚的路径,长 URL 网站收益更明显 |
这里最容易犯的错,是把 publisher 写成公司。个人网站不必硬凑 Organization,Schema.org 和 Google 文档都允许 Person 作为发布者,这比虚构一个“个人品牌组织”更准确。
它影响展示,不等于保证排名
结构化数据常被讲成 SEO 捷径,但现实更克制。Google Search Central 对结构化数据的公开表述一直是:它帮助搜索理解页面,并可能触发富结果展示;它不是排名承诺。换句话说,JSON-LD 更像网页的身份证和目录卡,不是搜索流量的提款机。
这也是它在 2026 年仍值得关注的原因。搜索结果、社交预览、知识图谱、AI 摘要都在更依赖机器可读信息。对独立开发者来说,一个项目页如果只写“我做了个 Rust CLI 工具”,机器很难判断它是文章、软件还是个人履历的一段;加上 SoftwareApplication、creator、sameAs 和价格为 0 的 offers,至少能把作品的身份说清。
但限制也很现实。爬虫是否抓取、是否信任、是否展示富结果,仍取决于搜索引擎自己的规则。Schema.org 类型很多,原文覆盖的只是对个人网站较有实际影响的一小部分。把页面塞满冷门字段,不会让内容自动变权威,反而增加维护成本。
对开发者的实际影响是少写但写准
受影响最大的是两类人:维护技术博客的开发者,以及把 GitHub、作品集、博客和项目页串在一起的独立站长。他们不需要上复杂 CMS,也不必为每个页面生成一大段重复 JSON。更现实的做法是把 Person 和 WebSite 做成模板,把 BlogPosting、BreadcrumbList、SoftwareApplication 按页面类型补上。
接下来最该观察的不是“排名涨没涨”,而是三件事:Google 富结果测试能否识别节点;搜索结果里的站点名、面包屑、文章信息是否更稳定;LLM 或抓取器引用个人信息时,是否能正确关联到同一个作者。若这些都没有变化,继续堆字段意义不大,应该回到内容质量、内链结构和页面可访问性这些基本功。