本地 AI 开始反攻云端:Google Gemma 4 与 LM Studio,让一台 MacBook 也能跑出“大模型尊严”
当云端 AI 不再总是优雅,本地模型突然变得很香
过去两年,开发者对云端大模型的感情很复杂。一方面,调用 API 的确方便,几行代码就能把 GPT、Claude、Gemini 接进工作流;另一方面,真正天天用的人都知道,云端服务一旦碰上速率限制、账单上涨、网络波动,体验就会从“丝滑”迅速掉到“想骂人”。更别提一些敏感任务——代码审查、内部文档整理、产品原型讨论——很多团队其实并不想把数据送出本地。
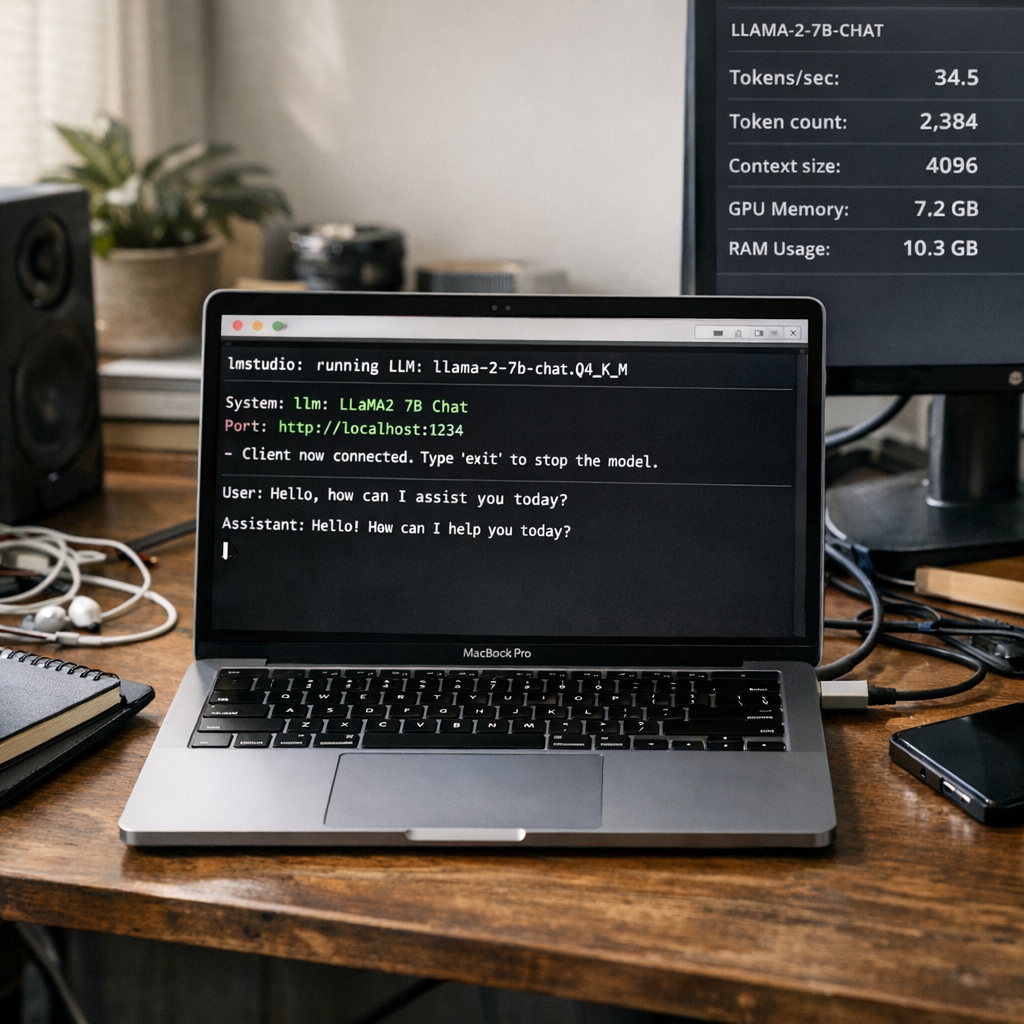
所以这件事的意义,不只是“Google 又发了一个新模型”,也不是“LM Studio 又加了一个命令行工具”这么简单。真正重要的是,本地 AI 终于越来越像一个严肃的生产力选项,而不是发烧友在深夜论坛里互相炫耀的跑分截图。根据原文作者的实测,Gemma 4 的 26B-A4B 版本可以在一台 14 英寸、48GB 统一内存的 MacBook Pro M4 Pro 上跑到每秒 51 个 token。这个数字放在今天,也许比不上云厂商集群里那些夸张的吞吐量,但它足够让人产生一种久违的安全感:断网也能用,没额度也能用,数据不出机器也能用。
这类安全感,正在成为 AI 时代的一种新基础设施。尤其是在开发者场景里,很多任务并不追求“全球最强模型”,而是追求“现在就能用、稳定可控、别让我多花钱”。从这个角度看,本地模型不是云 API 的替代品,更像是一种重新分配权力的工具。云端继续负责最强能力,本地则接管那些频繁、私密、碎片化的工作。
Gemma 4 真正厉害的地方,不是 26B,而是“会省力”
Gemma 4 这次最值得聊的,不是参数多大,而是 Google 在模型家族设计上越来越务实。它不是只端出一个“旗舰大一统”版本,而是做了四种不同路线:更轻的 E 系列、更强的 31B 稠密模型,以及这次很有代表性的 26B-A4B 混合专家模型,也就是 MoE。
MoE 这几年已经不是新鲜词了,但它在本地推理上的价值,直到最近才被越来越多人真正感受到。Gemma 4 26B-A4B 的总参数量在 26B 左右,可每次生成 token 时,只激活约 38 亿参数。你可以把它想象成一个很大的专家团,平时不需要所有人一起开会,只让最合适的几位上场。这样做的好处非常直接:模型整体能力维持在较高水平,推理成本却更接近一个小得多的稠密模型。
这就是为什么原文作者会把它视为 48GB Mac 的“甜点位”。如果你跑的是 31B 稠密模型,每次推理都要把所有参数拉上场,内存压力和速度都会更吃紧;如果退一步选更轻的小模型,速度是上来了,能力又往往差得明显。而 Gemma 4 26B-A4B 恰好卡在一个很微妙的位置:它在 MMLU Pro、AIME 这类指标上已经逼近更大的稠密模型,却还能在一台笔记本上相对舒适地跑起来。
这背后其实是一个行业趋势:大模型竞争正在从“谁更大”慢慢转向“谁更聪明地分配计算”。从 Mixtral,到 Qwen 的部分 MoE 版本,再到 GLM、Gemma,大家都在证明一件事——参数堆得越高,不等于落地就越好。尤其在本地场景里,真正的门槛不是理论能力,而是你能不能在普通人的机器上跑起来,跑得稳,还别把电脑风扇吹成直升机。
LM Studio 不再只是桌面玩具,它开始有点“基础设施”的样子了
如果说 Gemma 4 解决的是“模型值不值得本地跑”,那 LM Studio 0.4.0 解决的就是另一个更现实的问题:本地模型能不能别总停留在图形界面试玩阶段。
这次更新最关键的变化,是把推理核心拆成了独立的 llmster 服务,并配套推出 lms 命令行工具。听起来像一次普通版本更新,实际上却是在改游戏规则。过去很多本地模型工具都很好上手,但也很“桌面软件化”——适合点点按钮,不太适合进入自动化流程、服务器环境、SSH 远程会话,或者开发者日常的终端工作流。现在 LM Studio 把下载、加载、聊天、服务化调用都放进 CLI,本地模型终于更像一个可编排、可集成、可部署的组件了。
这件事为什么重要?因为开发者真正需要的,从来不是一个会聊天的漂亮窗口,而是一套能嵌进 CI/CD、脚本、编辑器插件和代理系统里的能力层。你可以用 lms daemon up 开一个后台服务,用 lms get 下载模型,用 lms load 挂载,再通过 API 或工具链调用它。对很多技术团队来说,这意味着本地模型第一次有机会成为“团队工具”,而不只是某个工程师电脑里的个人玩具。
LM Studio 还加入了并行请求处理、状态化 REST API,以及对 MCP 的本地支持。别小看这些听起来有点“工程味”的功能。今天的 AI 工具正在从单轮问答进化为能调工具、会记上下文、可处理多请求的半自治系统。如果底层推理引擎还停留在“一个窗口一段对话”的阶段,它很快就会掉队。LM Studio 显然也意识到了这一点,所以它不再只是在和 Ollama、llama.cpp 前端们竞争易用性,而是在争夺“本地 AI 操作系统入口”。
一台 48GB 的 MacBook,为什么突然像一台小型 AI 工作站
原文里最打动人的细节,不是任何一个 benchmark,而是那种很具体的、带点生活质感的描述:在一台 14 英寸 MacBook Pro M4 Pro 上,Gemma 4 26B-A4B 默认量化后占用约 17.99GB,48K 上下文时总内存需求约 21GB,拉到完整 256K 上下文,大约要 37.48GB。换句话说,一台高配一点的苹果笔记本,已经能容纳一个支持长上下文、支持视觉、支持工具调用,还带推理模式的大模型。
这在三年前几乎不可想象。那时本地跑大模型,意味着笨重的显卡塔式机、复杂的 CUDA 环境、动不动爆显存的焦虑。现在,苹果统一内存架构虽然有自己的局限,但它确实把“我就用一台笔记本干活”的体验推到了一个新层级。你不用单独考虑 VRAM 和系统内存怎么分家,也不用像拼乐高一样研究哪几层该丢到 GPU、哪几层塞回 CPU。对不少开发者和研究者来说,这种简化本身就是生产力。
当然,也不能把它说得太梦幻。本地跑模型依然有妥协。比如原文作者就提到,在 Claude Code 这样的工具链里接本地模型时,速度会明显变慢;并行推理会额外吃内存;上下文一旦开太大,机器上的其他应用空间就会被挤压。更现实的问题是,本地模型再快,也难以完全追上云端顶级闭源模型的综合表现。你得到的是控制权、隐私和低边际成本,失去的是一部分最前沿能力和“开箱即用”的稳定生态。
但这恰恰说明,本地 AI 的价值不该被拿来和云端旗舰做简单输赢比较。它更像家里的备用电源:平时也许不是最豪华的那个,但一旦你需要稳定、自主、持续可用,它就显得格外珍贵。
本地 AI 的下一场竞争,不只是模型,而是整条工具链
Gemma 4 和 LM Studio 放在一起看,透露出一个越来越清晰的行业信号:接下来的竞争,不会只发生在模型榜单上,也会发生在“模型怎样变得可用”这件事上。谁能把模型压缩得更聪明,谁能把量化、加载、上下文管理、并发处理、工具调用做得更顺滑,谁就更可能吃到本地 AI 普及的红利。
这一点上,Google 其实走在一个很有意思的位置。Gemma 系列不像 Gemini 那样承担商业 API 的明星任务,它更像 Google 对开源权重生态的一次“地面部队”投入。它既要保留 Google 模型设计的先进性,又得考虑开发者社区的真实硬件条件。某种程度上,Gemma 不是为了证明 Google 最强,而是为了证明 Google 也懂本地落地的逻辑。
对比来看,Meta 的 Llama 仍然有强大的社区惯性,阿里的 Qwen 在中文世界里生态扩张很快,Mistral 在高效推理和开放策略上也一直有存在感。Gemma 4 想真正站稳,光靠一次漂亮的性能曲线还不够,还得看后续量化版本是否丰富、社区适配是否及时、工具链是否持续跟进。毕竟本地 AI 这门生意,最终拼的不是实验室里的单点奇迹,而是开发者愿不愿意真的把它留在自己的工作流里。
我更关心的一个问题是:当越来越多开发者把本地模型接进 IDE、自动化脚本和企业内网后,云端大模型的护城河会不会开始变化?答案可能不是“云会被替代”,而是“云必须重新证明自己的溢价”。如果一个本地模型已经能完成 70% 到 80% 的日常任务,而且零 API 成本、零数据外流,那么云端服务剩下的优势,就必须集中在真正显著的能力差距上。对于整个 AI 行业来说,这反而是好事。竞争终于从“谁融资更多、谁卡更多 GPU”往“谁让用户更高效”这个方向走了。