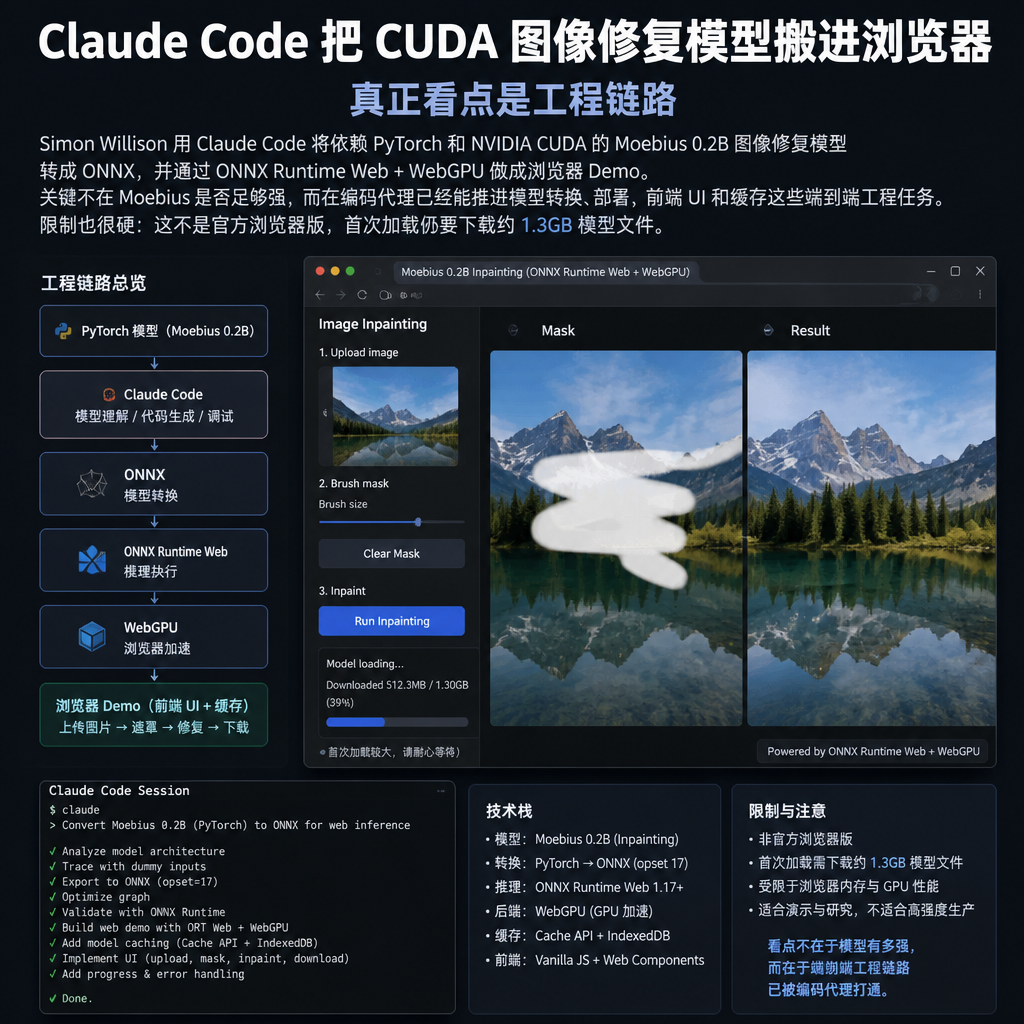
Simon Willison 6 月 22 日公开了一个个人移植项目:把 Moebius 0.2B 图像 inpainting 模型搬进浏览器。
Moebius 原发布版本依赖 PyTorch 和 NVIDIA CUDA。Willison 的做法是把模型转成 ONNX,再用 ONNX Runtime Web 的 WebGPU 后端在浏览器里跑。Demo 已经放在 GitHub Pages,ONNX 权重托管在 Hugging Face。
这个项目有意思的地方,不是 Moebius 一夜之间变成了“轻量网页应用”。恰恰相反,页面首次加载仍要拉约 1.3GB 文件。真正反常的是:一个编码代理在人的持续提示和验收下,已经能把模型转换、前端、部署、缓存这些脏活串起来。
从 CUDA 到 WebGPU:变的是入口,不是成本消失
Moebius 是一个 0.2B 参数级别的图像修复模型。用户标记图片中要移除的区域,模型补出空缺部分。原始项目面向 Python 和 NVIDIA CUDA 环境,不是面向普通网页用户。
Willison 的移植版也不是 Moebius 官方浏览器支持。它更像一次个人工程实验:把模型转换成 ONNX,用浏览器 GPU 能力执行,再做一个能上传图片、涂抹区域、点击运行的页面。
关键差异可以压成一张表:
| 对比项 | 原始 Moebius | Willison 移植版 | 实际含义 |
|---|---|---|---|
| 运行栈 | PyTorch + NVIDIA CUDA | ONNX Runtime Web + WebGPU | 从本地 CUDA 环境转到浏览器 GPU |
| 项目性质 | 官方发布模型与代码 | 个人移植 Demo | 不能理解为官方已支持浏览器 |
| 前端入口 | 需要本地工程环境 | GitHub Pages 页面 | 更容易给别人试用 |
| 权重位置 | Hugging Face 上的模型权重 | 约 1.24GB ONNX 权重托管在 Hugging Face | 页面首次加载约 1.3GB |
| 缓存处理 | 依赖本地环境 | CacheStorage API | 避免刷新时反复下载大文件 |
这里最值得看的是技术路线选择。Willison 一开始考虑过 Transformers.js,但最后走的是更底层的 ONNX Runtime Web。
这很合理。Transformers.js 对常见模型和 Hugging Face 生态更顺手,但遇到非标准结构时,ONNX Runtime Web 更像通用执行层。它不负责把体验包得很漂亮,重点是把计算图和权重交给浏览器执行。
对端侧 AI 开发者来说,这条路线给了一个现实参照:浏览器 AI 不只剩“套现成模型”一条路。非标准模型也可能被搬进网页,但代价是转换、算子兼容、内存、下载和缓存都要自己兜住。
这不是无成本迁移。
1.3GB 的首次下载,已经足以把很多消费级网页场景挡在门外。用户如果只想修一张图,可能不会等。企业如果要上线类似能力,也要先算带宽、等待时间和失败兜底。
Claude Code 做成了什么:不是自动驾驶,是可验收的工程推进
Willison 在原文里说得很直白:他基本没有读项目代码。
他做的事更像一个熟练开发者在带代理干活:先让 Claude 调研可行性,把研究结果存成 research.md;再让 Claude Code 写 plan.md 和 notes.md;中途把浏览器报错和截图贴回去;需要部署时,提供 Hugging Face token 和 GitHub Pages 的目标地址。
这不是“AI 自己完成一切”。人的角色没有消失,只是位置变了。
过去,把一个 PyTorch/CUDA 模型搬到浏览器,通常要有人熟悉几层东西:PyTorch 导出 ONNX、ONNX opset、WebGPU 后端、前端加载流程、大文件缓存、Hugging Face 托管。每一层都不算玄学,但串起来很费时间。
这次 Claude Code 至少表明一件事:编码代理已经能承担大量胶水工程。它能查资料、写转换脚本、搭 UI、处理部署,还能根据报错继续修。
但验收仍然在人手里。
Willison 持续给它目标、约束和反馈。比如页面每次刷新都会重新下载约 1.3GB 权重时,他提出要用 service worker 或类似办法缓存。Claude Code 去参考 Whisper Web,最后发现并使用了 CacheStorage API。
这个细节比“AI 写了很多代码”更有价值。因为真实工程里,难点常常不是写出第一版,而是发现第一版哪里不能给人用。
对技术管理者来说,行动建议也更具体:
| 对象 | 可以怎么做 | 不该怎么误判 |
|---|---|---|
| 做端侧 AI 的开发团队 | 把 coding agent 用在模型移植、Demo 验证、部署脚手架上,缩短探索周期 | 不要把一次 Demo 当成生产可用证明 |
| 评估代理编程的技术负责人 | 让资深工程师定义目标、边界和验收标准,再让代理跑工程链路 | 不要期待代理无人值守处理性能、许可、安全和兼容性责任 |
这类项目最适合当“探索工具”。如果团队想判断某个模型能不能进浏览器,可以先用代理做一轮移植验证。采购 GPU 服务、重写前端架构、押注某条端侧路线,都可以延后到 Demo 真的跑通之后。
换句话说,代理现在更像一台能跑得很快的工程小车。方向盘还在开发者手里。
浏览器端 AI 的边界:能跑之后,要看三件事
Willison 称自己在 Chrome、Firefox 和 Safari 中都试过这个 Demo。CacheStorage API 也能缓存约 1.3GB 的模型文件。
这对浏览器端 AI 是一个正向信号。图片修复这类能力,可以在客户端网页中完成。用户图片不必上传到服务器,这对隐私敏感场景有吸引力。
但“能跑”和“好用”之间,还有几道坎。
第一是下载体积。约 1.3GB 的首次加载,对桌面宽带用户还能接受,对移动网络和低耐心用户就很难。缓存能解决重复下载,解决不了第一次等待。
第二是设备差异。WebGPU 在主流浏览器里已经可用,但不同 GPU、驱动、内存限制会影响体验。原文只能说明作者在三大浏览器中试过,不等于各种设备都稳定。
第三是产品责任。Demo 可运行,不等于生产可交付。企业如果要放进产品,还要看模型许可、失败提示、带宽账单、低端设备降级方案,以及用户是否愿意为本地计算等待。
我更在意接下来三个变量:
- 非标准模型转 ONNX 的成功率,能不能从“靠高手带代理试出来”变成稳定流程。
- 浏览器缓存大模型文件,能不能形成可靠模式,而不是每个项目临时补洞。
- coding agent 在多轮调试中,能不能继续减少资深工程师介入次数。
如果这三件事有进展,浏览器端 AI 会先落在低频、高价值、隐私敏感的功能里。比如本地图片修补、音频转写、文档解析。它们不一定要求秒开,但要求数据少出门。
这也回到开头那 1.3GB。
它既是门槛,也是提醒:浏览器 AI 的入口变低了,工程账单没有消失。Claude Code 这次证明的不是魔法,而是代理已经能帮人把一串麻烦事推进到可验收。