Claude Code 创建者 Boris Cherny 上周五在 Meta @Scale 会议上,被问到一个很直接的问题:loops 是下一轮炒作,还是来真的?
他的回答也很直接:loops are for real。
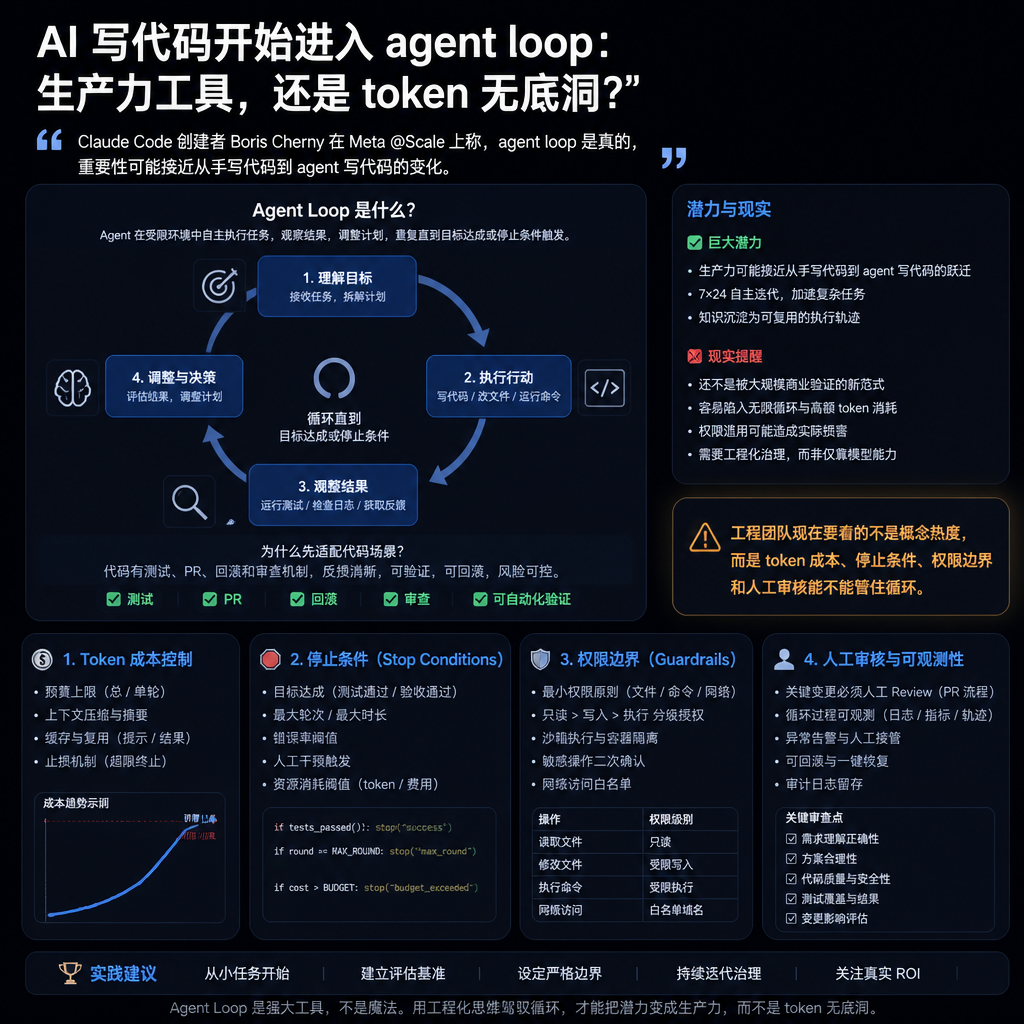
Cherny 还说,这件事的重要性,可能接近过去两年开发方式的变化:从人手写代码,到让 agent 写代码。现在再往前一步,是让一组 agent 长期在后台运行,甚至由一个 agent 提示另一个 agent 继续干活。
我更在意的不是“循环”这个词。循环和递归早就是编程里的基本功。新的地方在于,AI agent loop 把停止条件也变得不那么确定了:什么时候停、目标是否达成,可能不再只由一条硬规则决定,而是交给另一个子智能体判断。
这才是风险和机会都变大的地方。
agent loop 不是新概念,新在“后台不停干活”
传统 agent 更像一次性任务。你给它一个目标,比如修一个 bug、写一个测试、生成一个函数。它完成后停下来,人再检查结果。
agent loop 更像把任务挂到后台。它不是等人一次次下指令,而是持续寻找可改进的地方,执行、总结、判断,再进入下一轮。
差别大概在这里:
| 对比项 | 传统 agent 任务 | agent loop |
|---|---|---|
| 工作方式 | 接一个明确任务,完成后停止 | 长期后台运行,持续寻找下一步 |
| 停止条件 | 人设定,或任务完成 | 可能由子智能体判断目标是否达成 |
| 典型代码场景 | 修 bug、写测试、生成函数 | 架构清理、重复抽象合并、持续提交 PR |
| 主要风险 | 单次结果不准 | 成本失控、目标漂移、审核压力上升 |
这不是全新的计算机科学发明。不要把它包装成“循环被重新发明”。
更准确的说法是:agentic AI 把老的循环思想,放进了一个更难控制的执行环境里。过去循环跑错了,通常看条件、看日志、看栈。现在 agent 跑偏了,你还要判断它是不是“以为自己在完成目标”。
对开发者来说,这会改变日常工作重心。人不只是写提示词、看输出,还要设计循环的边界:它能看哪些仓库、能改哪些文件、能不能自动开 PR、多久必须停一次。
代码库为什么最先适配:因为有护栏,也有脏活
Cherny 举的例子很典型:一个 agent 持续寻找代码架构改进,另一个 agent 寻找可以合并的重复抽象。它们像程序员一样提交 pull request。
这个例子不夸张。代码库里确实有很多“长期没人想做,但做了有收益”的活:重复逻辑合并、测试补齐、静态分析修复、文档更新、依赖小升级。
这些任务适合 agent loop,有两个原因。
一是代码有可验证性。测试能跑,diff 能看,PR 能审,回滚路径也相对清楚。比起让 agent 长期处理合同、财务或客户沟通,代码场景至少有几道工程护栏。
二是代码库一直在变。只要主干持续更新,新的重复抽象、新的架构债、新的测试缺口就会出现。agent loop 的“持续性”在这里有用武之地。
但这也解释了它的边界。
如果一个后台 agent 每天开出十几个 PR,工程团队未必更轻松。审查、测试、合并、回滚都要人兜底。写代码的疲劳可能会变成审核机器产物的疲劳。
对工程负责人来说,比较现实的动作不是马上让 agent 接管核心系统,而是划一个低风险试验区:
- 从测试补齐、重复代码合并、文档更新、静态分析修复开始。
- 限制 agent 只能开 PR,不能直接合并。
- 给每个 loop 设 token 预算、运行时长和仓库权限。
- 要求每轮循环输出“做了什么、为什么继续、下一步是什么”。
这类试点不性感,但能看清真问题:agent 到底是在减少维护成本,还是在制造新的审查队列。
真门槛是成本、漂移和谁来按停键
agent loop 最大的商业问题,是账。
持续循环会快速消耗 token,而且理论上没有天然支出上限。对卖模型调用的公司,这是收入。对使用方,这是预算风险。
所以采购和技术管理者不该只问“能不能跑”。更该问四件事:
| 要问的问题 | 为什么重要 |
|---|---|
| 单个 loop 有没有预算上限 | 防止 token 消耗变成黑洞 |
| 停止条件由谁判断 | 防止 agent 自以为目标还没完成而持续运行 |
| 权限能否细分到仓库、目录和操作 | 防止低风险任务越界到核心代码 |
| PR 通过率、返工率、事故率能否统计 | 判断它是在提效,还是把成本转移给 reviewer |
这里还有一个更细的问题:长时间运行的模型会迷路。
开发者社区里常见的 Ralph Loop,就是一种补丁式技巧。它会让模型总结已经完成的工作,再反问目标是否已经达成。这个方法不神秘,更像给长跑中的 agent 定期点名、核对路线。
它能缓解漂移,但不能消灭漂移。
这也是我不太买账的一点:如果一个 loop 的安全性高度依赖提示词自我提醒,那它还不能算稳定工程能力。它可以是好工具,但不该被当成无人值守的同事。
目前能确认的,是 Cherny 的说法代表一线开发者实践正在变化。还不能确认的,是 agent loop 已经被大规模商业验证。也不能把 Cherny 的个人实践,直接等同于 Anthropic 的官方产品路线或行业共识。
接下来最该看的,不是发布会上谁把 loop 讲得更漂亮,而是三组硬指标:模型调用成本能否降到可长期运行;企业工具能否提供预算、权限和停止策略;agent 提交的 PR 在真实团队里的通过率、返工率和事故率如何。
如果这些指标站不住,agent loop 就会变成一种昂贵的自动化幻觉。
如果这些指标站得住,它才可能从开发者玩具,变成工程团队能放进流程里的生产力工具。
回到开头那个问题:loops 是不是真的?
是真的。但“真”不等于已经好用,更不等于可以放心放开跑。循环本身不值钱,能被管住的循环才值钱。