让 Claude 和 Codex 互相“结对编程”:AI 开始学会像同事一样干活了
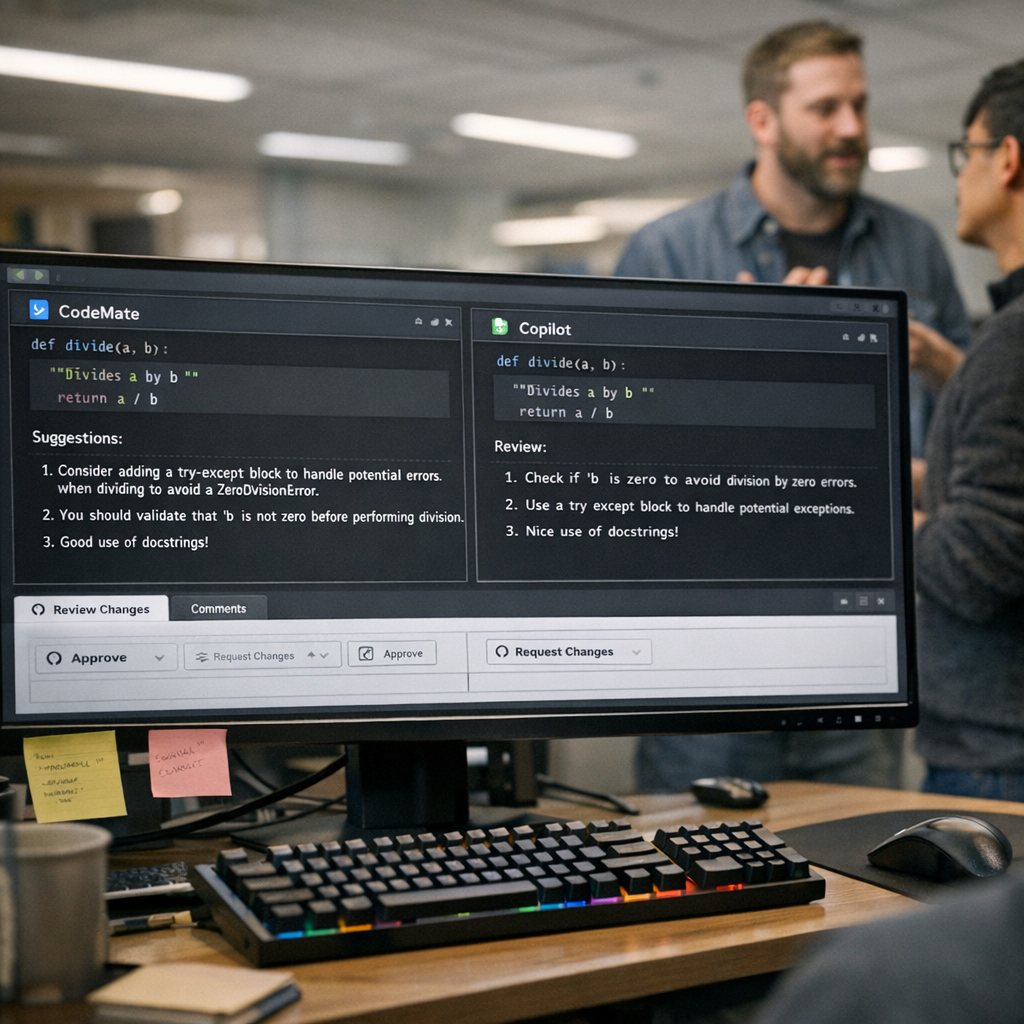
两个 AI 坐在一张“工位”上,代码审查突然没那么无聊了
如果你写过代码,大概率经历过那种微妙的时刻:一个同事说这段实现有边界条件没处理,另一个同事又补一句,命名也有点别扭。单看每条评论都不算致命,但当两个人同时盯上同一个问题时,你会本能地提高警惕——这通常不是噪音,而是信号。
Axel Delafosse 最近做的事情,本质上就是把这种人类团队里很常见的化学反应,搬到了 AI 身上。他写了一个名为 loop 的命令行工具,用 tmux 把 Claude 和 Codex 并排拉起来,再加一座“桥”,让两个模型可以直接交流。一个像主程序员,另一个像审稿人;也可以你来指定角色,或者随时插话。乍看有点像极客在周末捣鼓出来的玩具,但细想一下,这其实相当击中当下 AI 编程工具最核心的痛点:单个模型很强,可一旦进入真实软件开发流程,问题就不只是“会不会写”,而是“谁来复查、谁来纠偏、谁来保留上下文”。
有意思的是,Delafosse 在并行使用 Claude 和 Codex 做代码评审时发现,两者经常会给出不同视角的反馈;而当它们给出同样意见时,那种重复不但不烦,反而成了强烈信号。他提到,团队里如果两位 reviewer 意见一致,通常会 100% 处理。这种经验,做过工程的人都懂。AI 现在也开始呈现出类似特征:不是每一句话都值钱,但“共识”本身就是一种价值。
多代理不是新鲜事,真正的新鲜点是“让它们自己聊”
过去一年,AI 编程产品已经悄悄从“一个聊天框写代码”进化到了“一个主管带多个打工人”。Cursor 研究长时运行编码代理时,就发现多代理编排更像真正可落地的形态:主代理负责拆任务,子代理负责执行,再把结果汇报回来。这几乎就是软件团队的缩小版。Claude Code 的 Agent teams、Codex 的 Multi-agent,也都是同一思路的不同实现。
但这些系统大多有一个共同点:子代理通常只向“总控”汇报,很少彼此直接沟通。现实中的团队当然不是这样。一个后端工程师和一个测试工程师,不会凡事都先向项目经理汇报再转述,他们会先自己对齐。Delafosse 的实验动人之处就在这里:他没有再去追求一个“无所不能的大脑”,而是把注意力放在代理之间的横向沟通上。
这件事为什么重要?因为编程并不是单次问答任务,而是反复迭代、不断澄清、频繁返工的过程。今天 AI 写代码最常见的问题,不是生成能力不够,而是反馈回路太慢、上下文断裂太严重。你让模型改一个 bug,它改了;你再指出副作用,它又补;第三轮它可能把第一轮的意图忘了。人类结对编程之所以有效,不只是两个人更聪明,而是他们能在同一个语境里持续来回拉扯。loop 用很朴素的方法,把这种“持续对话的摩擦力”找回来了一点。
这不是魔法自动化,反而更像最老派的团队协作
AI 行业这两年很喜欢讲“自主代理”,听上去像是你下达一句命令,系统就会像魔法一样自动完成全部工作。但只要你真的把 AI 放进生产环境,就会发现工程世界没有那么浪漫。需求会变,边界会漏,测试会翻车,PR 会越改越大,最后总有人要回来收拾局面。
Delafosse 在文章里很坦诚地提到,loop 的好处之一,是它跑的是交互式 TUI,意味着人依然“在环路里”。你可以随时引导、回答问题、决定下一步,而不是把任务扔给一个黑盒代理后祈祷它别把仓库拆了。这种设计我个人是认同的。今天很多 AI 工具的宣传口径是“彻底自动化”,但成熟团队真正想要的,往往是“高质量的半自动协作”。人类不一定想亲手敲每一行代码,但也绝不愿意在系统已经走偏之后,才从一堆陌生提交里考古。
这让我想到一个有点反直觉的判断:AI 工作流的未来,也许不会越来越像科幻电影,反而会越来越像 Slack、GitHub、code review、standup meeting 这些你我早就熟悉的团队习惯。它看起来不够酷,却更接近现实。最有生命力的 agentic workflow,未必是完全替代人,而是把人类团队中已经被验证有效的协作模式——分工、复核、争论、交接——重新数字化,而且让 AI 也参与进来。
真正的难题,已经从“能不能写”转向“人怎么接手”
不过,别急着把它当成银弹。多代理协作带来的新问题,Delafosse 也点得很清楚:两个模型来回“循环”之后,往往会产出比预期更多的改动。这些改动很多时候是好的,甚至是惊喜,但对人类 reviewer 来说,审查成本会迅速上升。你原本只想修一个登录态 bug,最后 PR 里顺手重构了半个模块,测试补了,命名改了,文档也更新了——从工程洁癖角度看很舒服,从上线节奏角度看却让人头皮发麻。
这也是当下 AI 编程最容易被忽视的矛盾:模型越主动,人类越难 review。今天行业里还在兴奋讨论“AI 能不能独立提交 PR”,但真正成熟的问题其实是另一组:要不要把任务拆成多个 PR?计划文档该放在仓库里还是 PR 描述里?要不要附上一段录屏作为“工作证明”?这些听起来很琐碎,却是工程流程落地时避不开的现实。AI 可以帮你写代码,但它也在放大软件协作本来就存在的管理问题。
某种意义上,这比模型性能排行榜更值得关注。因为一旦公司真的让多代理进入日常开发,评估标准就不再只是 benchmark 分数,而是审计性、可追溯性、变更边界、团队信任感。一个代码写得再快的 agent,如果让 PR 变成“巨型谜团包”,团队也不会真心欢迎它。
一个小工具背后,是 AI 编程产品的下一轮分化
从更大的产业视角看,loop 还戳中了另一个趋势:越来越多开发者正在同时使用多个模型。原因五花八门,有人是为了避免被单一厂商锁定,有人是因为想兼顾闭源和开源,有人单纯是想把订阅费“用满”,当然也有人就是迷恋不同模型的性格差异——这个擅长规划,那个擅长补丁;这个解释更细,那个动手更快。
这会逼着 AI 编程工具进入下一轮分化。第一阶段大家比的是“谁更像 copilot”;第二阶段比“谁能自主完成更长流程”;接下来我更看好的竞争点,是“谁能成为多模型协作的平台层”。也就是说,产品不只是接一个最强模型,而是要把不同代理的通信、上下文共享、冲突消解、结果汇总做成一等公民。谁能把这层做好,谁才更有机会成为开发者真正离不开的工作台。
当然,这条路上还有不少挑战。不同厂商模型之间的协议并不统一,权限边界也很复杂;让代理彼此自由对话,意味着更高的 token 消耗、更长的执行链条,也可能把错误放大成“集体误判”。两个 AI 达成一致,不一定永远代表正确,它也可能只是共享了同一种偏见。这很像人类会议:共识有时是智慧,有时只是回音壁。如何让系统既能形成共识,又保留分歧,甚至主动暴露不确定性,会是下一步非常关键的产品设计题。
我喜欢 loop 的地方,不在于它已经把问题解决了,而在于它把问题问对了。它提醒我们,AI 编程的下一个突破,也许不是更会“单兵作战”的模型,而是更像一个真正团队的系统:有人写,有人挑刺,有人总结,人类则在关键节点拍板。听起来不那么神奇,却可能更接近软件开发的本质。
如果说前两年的 AI 编程像是在寻找一个天才实习生,那么从现在开始,行业真正要找的,可能是一支能合作、不甩锅、还愿意互相 code review 的虚拟工程团队。说实话,这比找一个天才更难,但也更有希望。毕竟写软件这件事,从来都不是一个人的战斗。